For optimal reading, please switch to desktop mode.
Spare a thought for CentOS users, it's been a bumpy ride for the last few years. CentOS 7 to 8 migrations, CentOS Linux 8 end-of-life, CentOS Stream. New RHEL clones such as Rocky Linux and Alma Linux stepping up to fill the void. How to respond?
In this blog post, we'll look at how these events affected us and our clients, and the steps we took to mitigate the risks involved in using CentOS Stream.
Timeline
Here is a brief timeline of the major events in the CentOS saga.
- 24th September 2019
- CentOS Linux 8 general availability. CentOS Stream 8 is introduced at the same time, described as an alternative, parallel distribution, upstream of RHEL, with a rolling release model.
- 16th October 2019
- OpenStack Train release general availability.
- 1st January 2020
- The end of life of Python 2 on January 1 2020 adds pressure to reinstall CentOS 7 systems with the then shiny new CentOS Linux 8.
- 8th December 2020
- CentOS project accelerates CentOS Linux end-of-life, bringing it forward by 8 years to 31st December 2021. CentOS Stream remains.
- 11th December 2020
- CentOS co-founder Gregory Kurtzer announces Rocky Linux, a RHEL clone.
- 31st December 2021
- RIP CentOS Linux :(
OpenStack Train release
The OpenStack Train release (not to be confused with the StackHPC Release train!) was a big one for the Kolla projects. With CentOS 7 providing insufficient support for Python 3, we needed to get to CentOS 8 to support Python 3 before the end-of-life of Python 2. Train therefore needed to support both CentOS 7 (with Python 2) and CentOS 8 (with Python 3), and to provide a route for migration. Major OS version upgrades are not supported in CentOS, so a reinstall is required. The Kolla Ansible spec provides some of the gory details.
It took significant development effort to make this migration possible. While the automation provided by Kayobe and Kolla Ansible helps significantly to perform the migration, it still involves significant operator effort to reinstall each host and keep the cloud running.
CentOS Linux EOL
Having fairly recently migrated our clients' systems to CentOS 8, the announcement of the end-of-life of CentOS Linux came as quite a blow. It also required us to make a decision about how to proceed.
Should we jump into the Stream? CentOS Stream seemed to divide the community, with some claiming it to be not production-ready, and others having faith in its CI testing.
Should we try out one of the new RHEL clones? Rocky Linux seemed promising, but would not be released until June 2021, and would need to build a sustainable community around it to be viable.
Should we switch to another distribution entirely? We started development of Ubuntu support for Kayobe around this time. Tempting, but migrating from CentOS to Ubuntu could be a bigger challenge than migrating from CentOS 7 to 8, and a hard sell for our existing clients.
Taking the plunge
In the end, with a little encouragement from the direction taken by CERN, we learned to stop worrying and deploy CentOS Stream. Of course, in order to stop worrying, we needed to mitigate the risks of using a rolling release distribution.
CentOS Linux was a rebuild of RHEL, meaning that it followed the same release cycle, albeit delayed by a few weeks. The main CentOS mirrors served the latest minor release (e.g. 8.2), and were updated every few months with a new minor release. Security patches and critical bug fixes were applied between minor releases. While the minor releases sometimes introduced issues that needed to be fixed or worked around, this model provided fairly long periods of stability.
With CentOS Stream, there is a constant trickle of updates, and the state at any point lies somewhere between one minor release of RHEL and the next. In fact, it may be worse than this, if packages are upgraded then downgraded again before the next minor RHEL release. There is some CI testing around changes to Stream, however clearly it won't be as rigorous as the testing applied to a RHEL minor release.
Islands in the Stream
How to cope with this instability? For StackHPC, the answer lies in creating snapshots of the CentOS Stream package repositories. Stable, tested islands in the stream.
This approach is one we had been starting to apply to some of our client deployments, even with CentOS Linux. Having a local mirror with repository snapshots improves repeatability, as well as reducing dependence on an external resource (the upstream mirrors), and avoiding a fan-in effect on package downloads from the Internet.
This approach worked well for a while, but it soon became clear that having separate package repositories for each deployment was not optimal. Each site was using a different set of packages, a different set of locally-built container images, and no common source of configuration beyond that provided by Kayobe and Kolla Ansible. Without some changes, this would soon become a scaling bottleneck for the company.
Release Train
As they say, never waste a good crisis. CentOS Stream gave us an opportunity to take the StackHPC Release Train project off of our (long) backlog. It's an effort to make our OpenStack deployments more consistent, reproducible and reliable, by releasing a set of tested artifacts. This includes:
- Package repositories
- Kolla container images
- Binary artifacts (images, etc.)
- Source code repositories
- Kayobe and Kolla configuration
We are initially targeting CentOS Stream, but we will likely add support for other distributions.
Pulp
We use Pulp to manage and host content for the release train. Pulp is a content server that manages repositories of software packages and facilitates their distribution to content consumers. It is implemented in Python using the Django framework, and is composed of a core and plugins for the various content types (e.g. RPMs, containers). A key feature of Pulp is fine-grained control over snapshots of repositories.
Pulp concepts
It's useful to have an awareness of the core concepts in Pulp, since they are common to the various plugins.
- Repository
- A pulp repository of artifacts & metadata
- Remote
- A remote repository
- Repository version
- A snapshot of a repository at a point in time
- Sync
- Sync a repository with a remote, creating a repository version
- Publication
- A published repository version, including metadata
- Distribution
- Content made available to users
For example, the RPM plugin might have a centos-baseos repository, which syncs from the upstream centos-baseos remote at http://mirror.centos.org/centos/8-stream/BaseOS/, creating a new repository version when new content is available. In order to make the content available, we might create a publication of the new repository version, then associate a centos-baseos-development distribution with the publication. Another centos-baseos-production might be associated with an older publication and repository version. Pulp can serve both distributions at the same time, allowing us to test a new snapshot of the repository without affecting users of existing snapshots.
Automation & Continuous Integration (CI)
Automation and CI are key aspects of the release train. The additional control provided by the release train comes at a cost in maintenance and complexity, which must be offset via automation and CI. In general, Ansible is used for automation, and GitHub Actions provide CI.
The intention is to have as much as possible of the release train automated and run via CI. Typically, workflows may go through the following stages as they evolve:
- automated via Ansible, manually executed
- executed by GitHub Actions workflows, manually triggered by workflow dispatch or schedule
- executed by GitHub Actions workflows, automatically triggered by an event e.g. pull request or another workflow
This sequence discourages putting too much automation into the GitHub Actions workflows, ensuring it is possible to run them manually.
We typically use Ansible to drive the Pulp API, and have made several contributions to the squeezer collection. We also created the stackhpc.pulp Ansible collection as a higher level interface to define repositories, remotes, and other Pulp resources.
Architecture
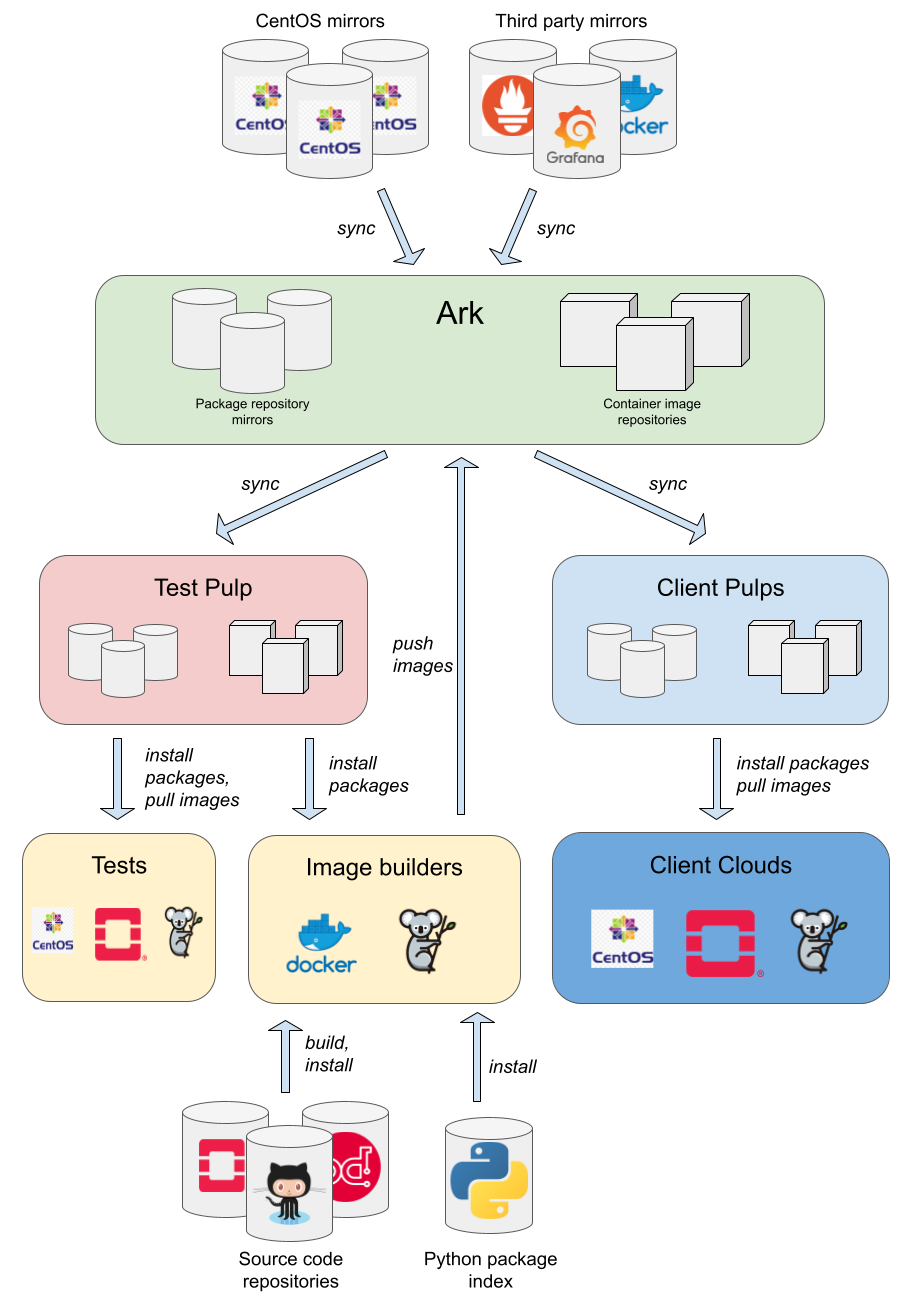
Ark is our production Pulp server, and is hosted on Leafcloud. It comprises a single compute instance, with content stored in Leafcloud's object storage. We use pulp_installer to deploy Pulp. It is the master copy of development and released content. Access to the API and artifacts is controlled via client certificates and passwords.
Clients access Ark via a Pulp service deployed on their local infrastructure. Content is synced from Ark to the local Pulp service, and control plane hosts acquire the content from there.
A test Pulp service runs on the SMS lab cloud. Content is synced from Ark to the test Pulp service, where it is used to build container images and run tests. In some respects, the test Pulp service may be considered a client.
Content types
Various different types of content are hosted by Pulp, including:
- RPM package repositories (Pulp RPM plugin)
- CentOS distribution packages
- Third party packages
- Container image repositories (Pulp container plugin)
- Kolla container images
We also anticipate supporting the following content:
- Apt package repositories (Pulp Deb plugin)
- Ubuntu distribution packages
- Third party packages
- File repositories (Pulp file plugin)
- Disk images
Some of this content may be mirrored from upstream sources, while others are the result of release train build processes.
Access control
Access to released Pulp content is restricted to clients with a support agreement. Build and test processes also need access to unreleased content.
Access to package repositories is controlled via Pulp x509 cert guards. A HashiCorp Vault service acts as a Certificate Authority (CA) for the cert guards. Two cert guards are in use - development and release. The development cert guard is assigned to unreleased content, while the release cert guard is assigned to released content. Clients are provided with a client certificate which they use when syncing package repositories in their local Pulp service with Ark. Clients' client certificates are authorised to access content protected by the release cert guard. Build and test processes are provided with a client certificate that is authorised to access both the development and release cert guards. The latter is made possible via the CA chain.
Access to container images is controlled by token authentication, which uses Django users in the backend. Two container namespaces are in use - stackhpc-dev and stackhpc. The stackhpc-dev namespace is used for unreleased content, while the stackhpc namespace is used for released content. Clients are provided with a set of credentials, which they use when syncing container image repositories in their local Pulp service with Ark. Clients' credentials are authorised to pull from the stackhpc namespace. Build and test processes are provided with credentials that are authorised to push to the stackhpc-dev namespace.
Syncing package repositories
The stackhpc-release-train repository provides Ansible-based automation and Github Actions workflows for the release train.
A Github Actions workflow syncs CentOS Stream and other upstream package repositories nightly into Ark, creating new snapshots when there are changes. The workflow may also be run on demand. Publications and distributions are created using the development content guard, to ensure that untested content is not accessible to clients. We sync using the immediate policy, to ensure content remains available if it is removed from upstream mirrors. This workflow also syncs the content to the test Pulp service.
Package repository distributions are versioned based on the date/time stamp at the beginning of the sync workflow, e.g. 20211122T102435. This version string is used as the final component of the path at which the corresponding distribution is hosted. For example, a CentOS Stream 8 BaseOS snapshot may be hosted at https://ark.stackhpc.com/pulp/content/centos/8-stream/BaseOS/x86_64/os/20220105T044843/.
The rationale behind using a date/time stamp is that there is no sane way to version a large collection of content, such as a repository, in a way in which the version reflects changes in the content (e.g. SemVer). While the timestamp used is fairly arbitrary, it does at least provide a reasonable guarantee of ordering, and is easily automated.
Building container images
Kolla container images are built from the test Pulp service package repositories and pushed to the Ark container registry.
Build and test processes run on SMS cloud, to avoid excessive running costs. All content in Ark that is required by the build and test processes is synced to the test Pulp service running in SMS cloud, minimising data egress from Ark.
Kolla container images are built via Kayobe, using a builder environment in StackHPC Kayobe config. The configuration uses the package repositories in Ark when building containers. Currently this is run manually, but will eventually run as a CI job. The stackhpc-dev namespace in Ark contains container push repositories, which are pushed to using Kayobe. (Currently this is rather slow due to a Pulp bug.)
A Github Actions workflow runs on demand, syncing container repositories in test Pulp service with those in Ark. It also configures container image distributions to be private, since they are public by default.
Kolla container images are versioned based on the OpenStack release name and the date/time stamp at the beginning of the build workflow, e.g. wallaby-20211122T102435. This version string is used as the image tag. Unlike package repositories, container image tags allow multiple versions to be present in a distribution of a container repository simultaneously. We therefore use separate namespaces for development (stackhpc-dev) and release (stackhpc).
Testing
Release Train content is tested via a Kayobe deployment of OpenStack. An aio environment in StackHPC Kayobe config provides a converged control/compute host for testing. Currently this is run manually, but will eventually run as a CI job.
Promotion
Whether content is mirrored from an upstream source or built locally, it is not immediately released. Promotion describes the process whereby release candidate content is made into a release that is available to clients.
For package repositories, promotion does not affect how content is accessed, only who may access it. Promotion involves changing the content guard for the distribution to be released from development to release. This makes the content accessible to clients using their x.509 client certificates.
The stackhpc container namespace contains regular container repositories, which cannot be pushed to via docker push. Instead, we use the Pulp API to sync specific tags from stackhpc-dev to stackhpc.
Configuration
StackHPC maintains a base Kayobe configuration which includes settings required to consume the release train, as well as various generally applicable configuration changes. Release Train consumers merge this configuration into their own, and apply site and environment-specific changes. This repository provides configuration and playbooks to:
- deploy a local Pulp service as a container on the seed
- define which package repository versions to use
- define which container image tags to use
- sync all necessary content from Ark into the local Pulp service
- use the local Pulp repository mirrors on control plane hosts
- use the local Pulp container registry on control plane hosts
This configuration is in active development and is expected to evolve over the coming releases. It currently supports the OpenStack Victoria and Wallaby releases.
Further documentation of this configuration is available in the readme.
All aboard
In the second half of 2021, with the end-of-life of CentOS Linux looming large, the pressure to switch our clients to CentOS Stream was increasing. We had to make some tough calls in order to implement the necessary parts of the release train and put them into production. The StackHPC team then had to work hard migrating our clients' systems to our new release train and CentOS Stream.
Of course, there were some teething problems, but overall, the adoption of the release train went fairly smoothly.
Release Train day 2
Clouds don't stand still, and at some point something will require a patch. How well does the release train cope with changes? A test soon came in the form of a zero-day Grafana exploit, CVE-2021-43798. Grafana applied fixes and cut some releases. We needed to get the updated packages into our Grafana container image, and roll it out to affected deployments. This turned out to be a little more clunky than I'd hoped, with repository snapshot versions tracked in multiple places, and various pull requests. It looked a bit like this:
- Manual package repository sync (the previous night's sync had failed)
- Update test repo versions, commit only grafana version bump in stackhpc-release-train repository
- Sync and publish repos in test pulp service
- Bump grafana repository version in stackhpc-kayobe-config repository
- Build & push grafana image
- Promote container images with the new tag
- Sync container images to test Pulp service
- Bump grafana container image tag in stackhpc-kayobe-config repository
- Test the new container
Needless to say, this could be simpler. However, it was a good catalyst for some head scratching and a whiteboard session with Matt Anson, resulting in a design for release train mk2.
Release Train mk2
The changes in mk2 are mostly quite subtle, but the key shift was to using stackhpc-kayobe-config as the single source of truth for all repository versions and container image tags. The stackhpc-release-train repository would not include any 'live' state, just a set of Ansible playbooks and Github Actions workflows to drive the various workflows.
Another change in mk2 is around the branching model for stackhpc-kayobe-config, adding the ability to stage changes for an upcoming release, without making them available to clients. There are also some usability improvements to the automation, making it easier to perform actions changes on specific package repositories or container images.
Next stop?
Where next for the release train? Within the current scope of package repositories and container images, there is plenty of room for improvement. Usability enhancements, more automation and CI, and better automated building security scanning and testing of changes before they are released. We'll also likely expand to support other distributions than CentOS Stream.
Release Train also has ambitions around our source code, improving our development processes with better CI, more automation for our (few) repositories with downstream changes, and increased reproducibility of builds and installations.
Another avenue for growth of the release train is moving up the stack to our platforms, such as Slurm and Kubernetes.
CentOS Stream in retrospect
Overall, our experience with CentOS Stream has been acceptable, given the steps we have taken to mitigate risks of unexpected changes. Indeed, there have been a few occasions where changes in Stream have broken the Kolla upstream CI jobs, that we have been insulated from.
There are some other downsides to Stream. Mellanox does not publish OFED packages built against Stream, only RHEL minor releases. While it is generally possible to force the use of a compatible kernel in Stream, this kernel will not receive the security updates that a RHEL minor release kernel would. In many cases it may be possible to use the in-box Mellanox drivers, however these may lack support for some of the latest hardware or features. This is a consideration for the points where we make our snapshots.
Kayobe and Kolla Ansible have recently added support for Rocky Linux as a host OS, as well as the ability to run libvirt as a host daemon rather than in a container. This reduces the coupling between the host and containers, making it safer to mix their OS distributions, e.g. running Rocky hosts with CentOS Stream container images.
Resources
Get in touch
If you would like to get in touch we would love to hear from you. Reach out to us via Bluesky or directly via our contact page.