For optimal reading, please switch to desktop mode.
In scientific disciplines, large-scale computing was historically the preserve of the physical sciences. With the advent of disciplines like bioinformatics and data science, in later years it has become a central theme of the life and social sciences too.
High Performance- and High Throughput Computing (HPC and HTC) developed to support these endeavours. Traditionally, institutions and organisations have a central HPC system with a job scheduler that fairly queues up requests for an allocation of computing infrastructure. The "fairness weighting" of a request can depend on many factors - the overall utilisation of the HPC system, the "dimensions" (CPU, memory and duration) of the request, and whether additional hardware resources - like a GPU - are required.
Fair isn't always flexible - enter the cloud!
The requirements of modern science workloads frequently depart from the environment provided by traditional HPC configurations. Analysis software might require a specific operating system, or it's RAM requirements may exceed the available RAM in a traditionally specced HPC compute node. Additionally, data-science-heavy disciplines making use of Artificial Intelligence (AI) and Machine Learning (ML) often depend on interactive and collaborative exploration of data using tools like Jupyter Notebooks.
Enter the cloud! Using cloud computing infrastructure unlocks complete flexibility for researchers - you can use an operating system that fits the requirements of your software tooling, you can configure your environment exactly as you like because you are able to use the root account, and you can pick a "flavour" (or specification) of your compute environment to exactly fit your workload.
Flexibility almost always means complexity
While the promise of the flexibility of cloud computing is great, the reality is that flexibility introduces complexity. Configuring your own scientific computing environment from scratch in the cloud isn't always the most intuitive process, particularly when you don't have a background in managing or operating compute infrastructure. Configuring virtual networking, security groups and SSH keys are notorious barriers to researchers becoming productive in the cloud in a performant and secure way.
Introducing Azimuth
Azimuth provides a self-service portal for managing long(er)-lived cloud resources - "science platforms" - with a focus on simplifying the use of cloud for scientific computing and artificial intelligence (AI) use cases. It is currently capable of targeting OpenStack clouds, which many organisations and institutions provide as an on-premise private cloud, although it is specifically architected to be cloud-agnostic.
Azimuth is based on prior work with JASMIN Cloud and is a simplified version of the OpenStack Horizon dashboard, with the aim of reducing the "getting-started" complexity for users that don't have a background in running compute infrastructure. Azimuth abstracts away complexity with opinionated, safe default configuration to enable scientists and researchers to "get on with the science" without ever having to encounter cloud-specific concepts like virtual networking or security groups. It offers functionality with a focus on simplicity for scientific use cases, including the ability to create complex science platforms via a user-friendly web interface.
Science platforms range from single-machine workstations with graphical desktops and consoles available securely via the web, to entire multi-server Slurm clusters and platforms such as JupyterHub and other Kubernetes-native platforms. It even supports creating Sonobuoy-conformant Kubernetes clusters that you can use to provide an execution environment for your favourite workflow manager!
Azimuth science platforms
StackHPC distribute a range of science platforms with Azimuth which, after extensive feedback from the JASMIN and other science communities, aim to enable a variety of science workloads.
| Linux workstation |
|
| Jupyter Notebook |
|
| Slurm batch computing cluster |
|
| Kubernetes cluster |
|
| JupyterHub/DaskHub/Pangeo |
|
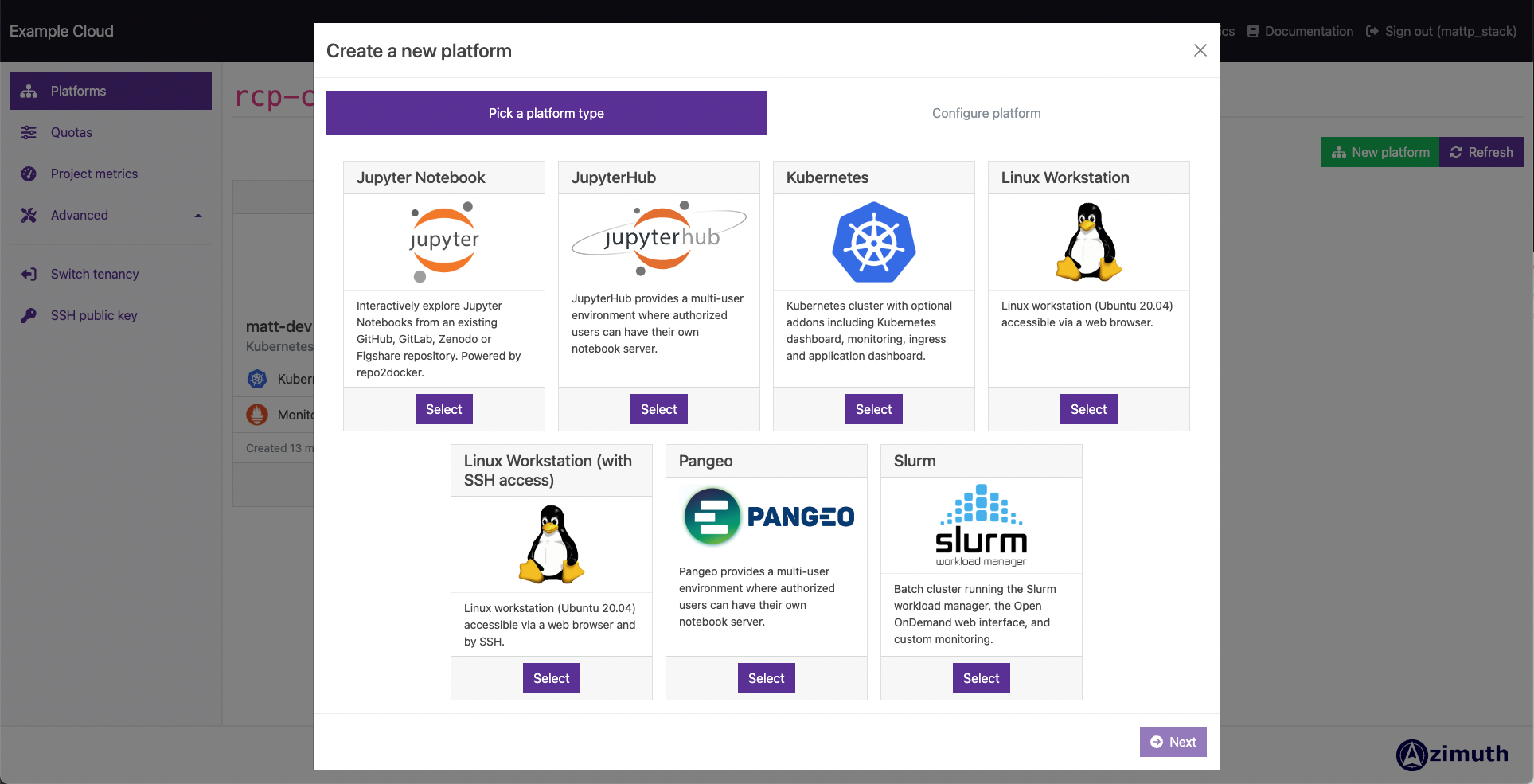
All platforms come with their own monitoring stack based on Prometheus and Grafana, which is accessible via a web browser, this gives immediate insights into how your workload interacts with your compute environment.
Try Azimuth
Azimuth is free and open-source, and it is designed to run on the same OpenStack cloud that it creates science platforms on.
If your organisation uses OpenStack to provide cloud infrastructure, and you are a cloud operator or a keen researcher with some OpenStack quota - we provide an easy-to-deploy demo configuration, which you can use to try Azimuth on your own cloud.
For production-ready deployments and further information on the inner-workings of Azimuth, we provide an in-depth guide to continuous deployment, management and architecture of Azimuth.
Acknowledgements
StackHPC greatly appreciate the support provided through the Science and Technology Facilities Council (STFC), and in particular the IRIS, DiRAC and JASMIN communities.
Get in touch
If you would like to get in touch we would love to hear from you. Reach out to us via Bluesky or directly via our contact page.