For optimal reading, please switch to desktop mode.
Background
The Human Brain Project (HBP) is a 10-year EU FET flagship project seeking to “provide researchers worldwide with tools and mathematical models for sharing and analysing large brain data they need for understanding how the human brain works and for emulating its computational capabilities”. This ambitious and far-sighted goal has become increasingly relevant during the lifetime of the project with the rapid uptake of Machine Learning and AI (in its various forms) for a broad range of new applications.
A significant portion of the HBP is concerned with massively parallel applications in neuro-simulation, in analysis techniques to interpret data produced by such applications, and in platforms to enable these. The advanced requirements of the HBP in terms of mixed workload processing, storage and access models are way beyond current technological capabilities and will therefore drive innovation in the HPC industry. The Pre-commercial procurement (PCP) is a funding vehicle developed by the European Commission, in which an industrial body co-designs with a public institution an innovative solution to a real-world technical problem, with the intention of providing the solution as commercialized IP.
The Jülich Supercomputer Centre on behalf of the Human Brain Project entered into a competitive three-phased PCP programme to design next-generation supercomputers for the demanding brain simulation, analysis and data-driven problems facing the wider Human Brain Project. Two consortia - NVIDA and IBM, and Cray and Intel were selected to build prototypes of their proposed solutions. The phase III projects ran until January 2017, but Cray’s project deferred significant R&D investment, and was amended and extended. Following significant activity supporting the research efforts at Jülich, JULIA was finally decommissioned at the end of November.
Introducing JULIA

In 2016, Cray installed a prototype named JULIA, with the aim of exploring APIs for access to dense memory and storage, and the effective support of mixed workloads. In this context, mixed workloads may include interactive visualisation of live simulation data and the possibility of applying feedback to "steer" a simulation based on early output. Flexible exploitation of new hardware and software aligns well with Cray's vision of adaptive supercomputing.
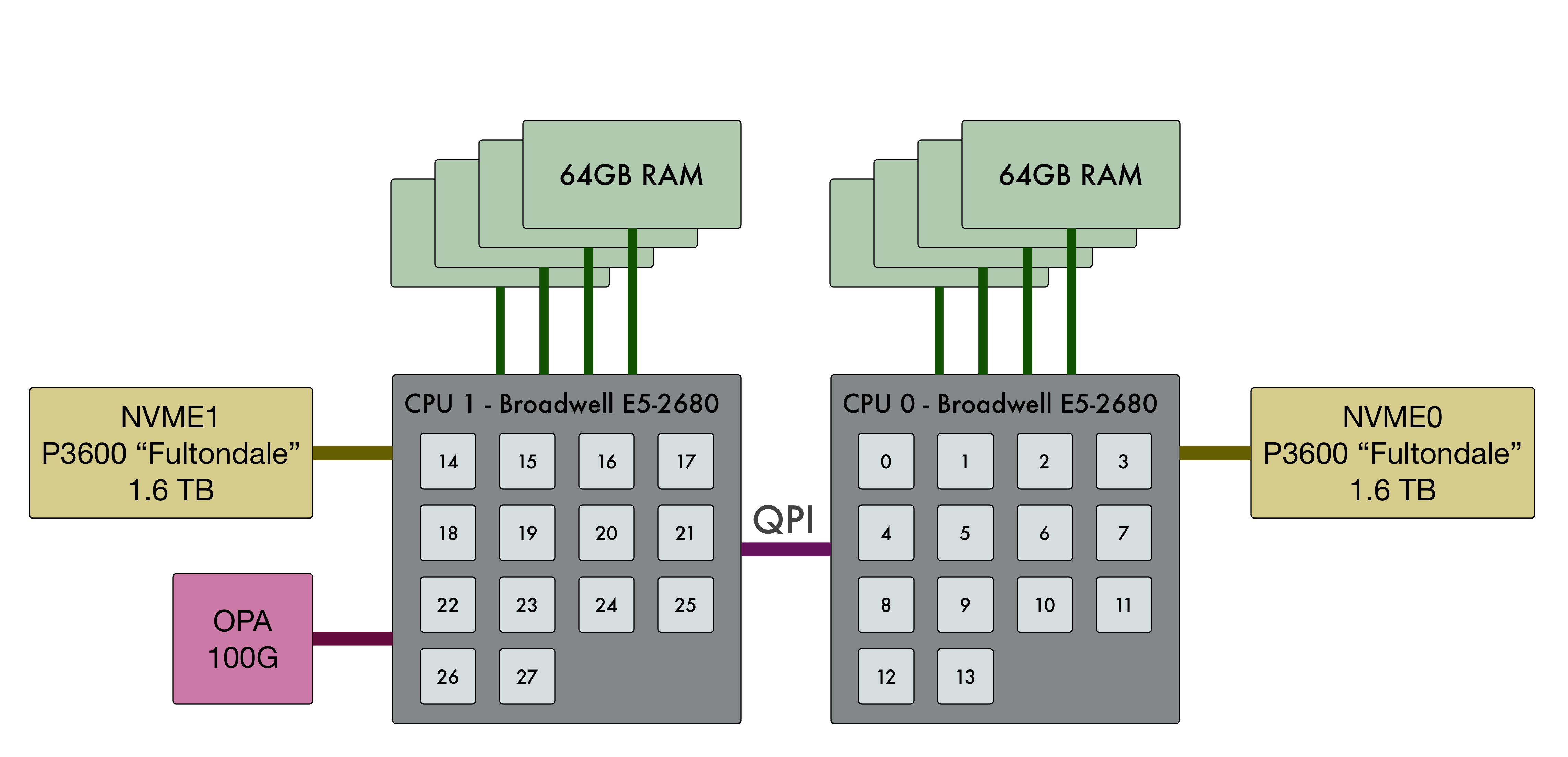
JULIA is based on a Cray CS400 system, but extended with some novel hardware and software technologies:
- 60 Intel Knights Landing compute nodes
- 8 visualisation nodes with NVIDIA GPUs
- 4 data nodes with Intel Xeon processor and 2x Intel Fultondate P3600 SSDs
- All system partitions connected using the Omnipath interconnect
- Installation of a remote visualization system for concurrent, post-processing and in-transit visualization of data primarily from neurosimulation.
- An installed software environment combining conventional HPC toolchains (Cray, Intel, GNU compilers), and machine learning software stacks (e.g. Theano, caffe, TensorFlow)
- A storage system consisting of SSD-backed Ceph
StackHPC was sub-contracted by Cray in order to perform analysis and optimisation of the Ceph cluster. Analysis work started in August 2017.
Ceph on JULIA
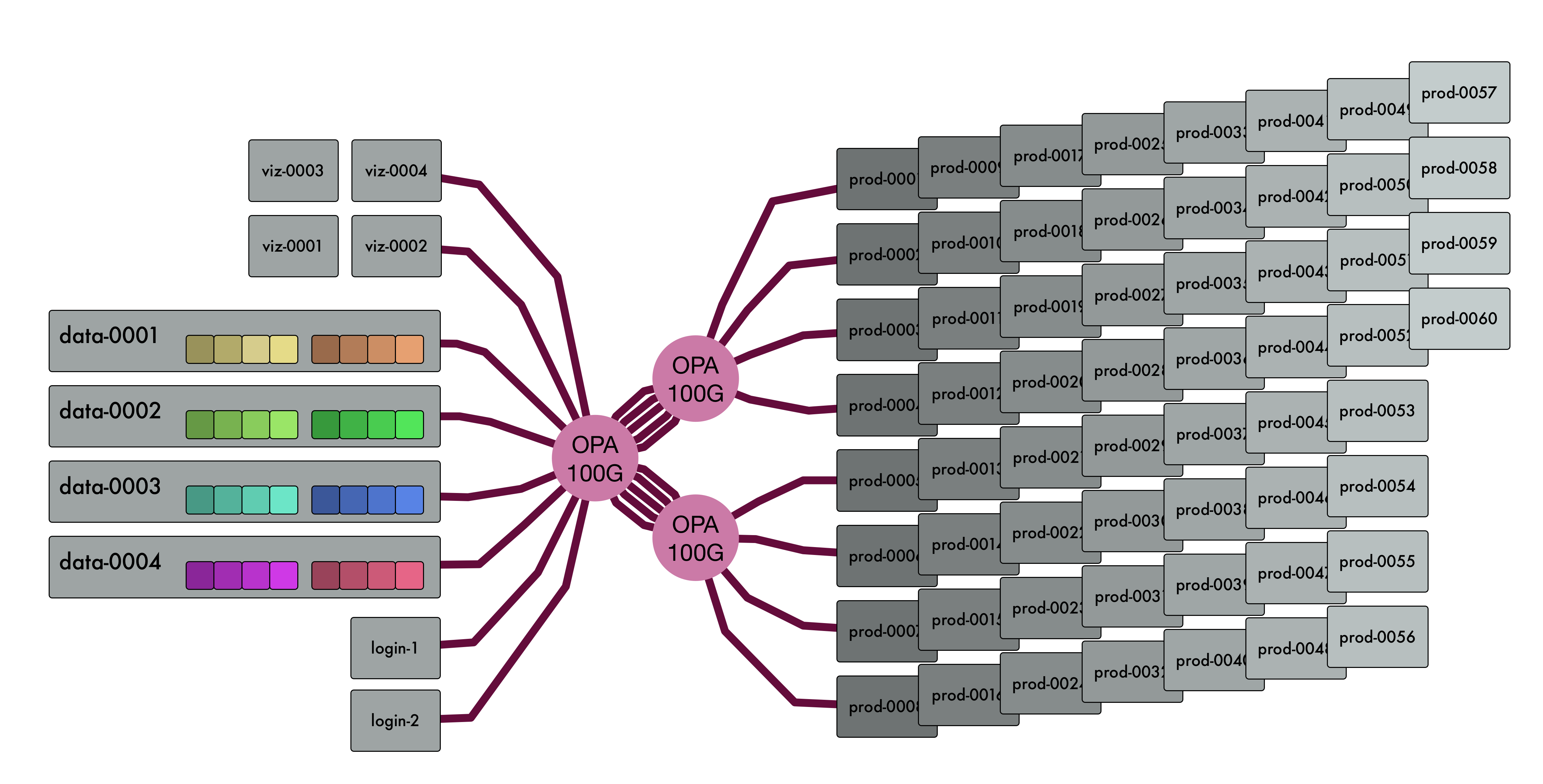
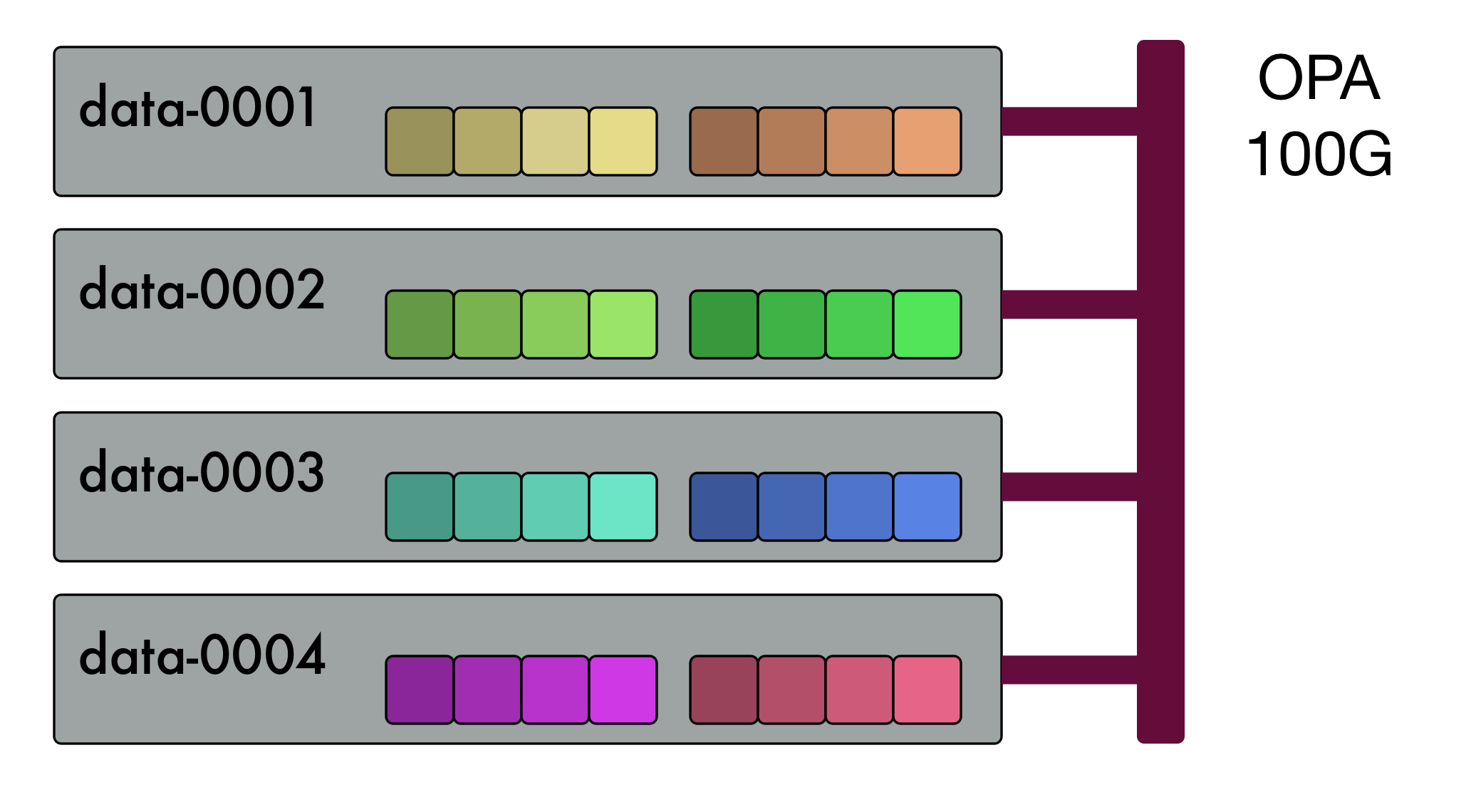
The Ceph infrastructure comprises four data nodes, each equipped with two P3600 NVME devices and a 100G Omnipath high-performance network:
Each of the NVME devices is configured with four partitions. Each partition is provisioned as a Ceph OSD, providing a total of 32 OSDs.
The Ceph cluster was initially running the Jewel release of Ceph (current at the time). After characterising the performance, we started to look for areas for optimisation.
High-Performance Fabric
The JULIA system uses a 100G Intel Omni-Path RDMA-centric network fabric, also known as OPA. This network is conceptually derived and evolved from InfiniBand, and reuses a large proportion of the InfiniBand software stack, including the Verbs message-passing API.
Ceph's predominant focus on TCP/IP-based networking is supported through IP-over-InfiniBand, a kernel network driver that enables the Omni-Path network to carry layer-3 IP traffic.
The ipoib network driver enables connectivity, but does not unleash the full potential of the network. Performance is good on architectures where a processor core is sufficiently powerful to maintain a significant proportion of line speed and protocol overhead.
This sankey diagram illustrates the connectivity between different hardware components within JULIA:
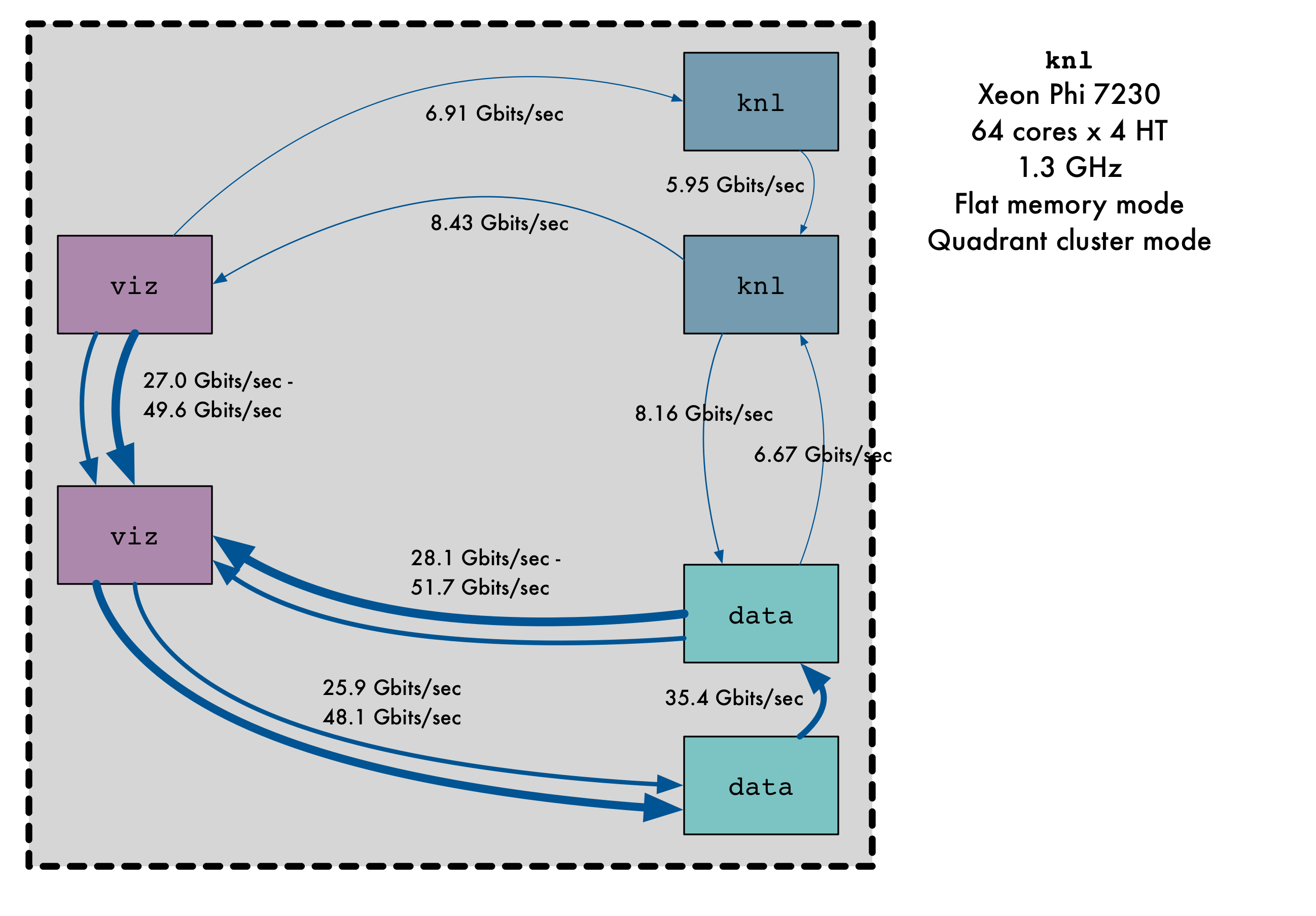
In places there are two arrows, as the TCP performance was found to be highly variable. Despite some investigation, the underlying reason for the variability is still unclear to us.
Using native APIs, Omni-Path will comfortably saturate the 100G network link. However, the ipoib interface falls short of the mark, particularly on the Knights Landing processors.
Raw Block Device Performance
In order to understand the overhead of filesystem and network protocol, we attempt to benchmark the system at every level, moving from the raw devices up to the end-to-end performance between client and server. In this way, we can identify the achievable performance at each level, and where there is most room for improvement.
Using the fio I/O benchmarking tool, we measure the aggregated block read performance of all NVME partitions in a single JULIA data server. We used four fio clients per partition (32 in total) and 64KB reads. The results are stacked to get the raw aggregate bandwidth for single node:
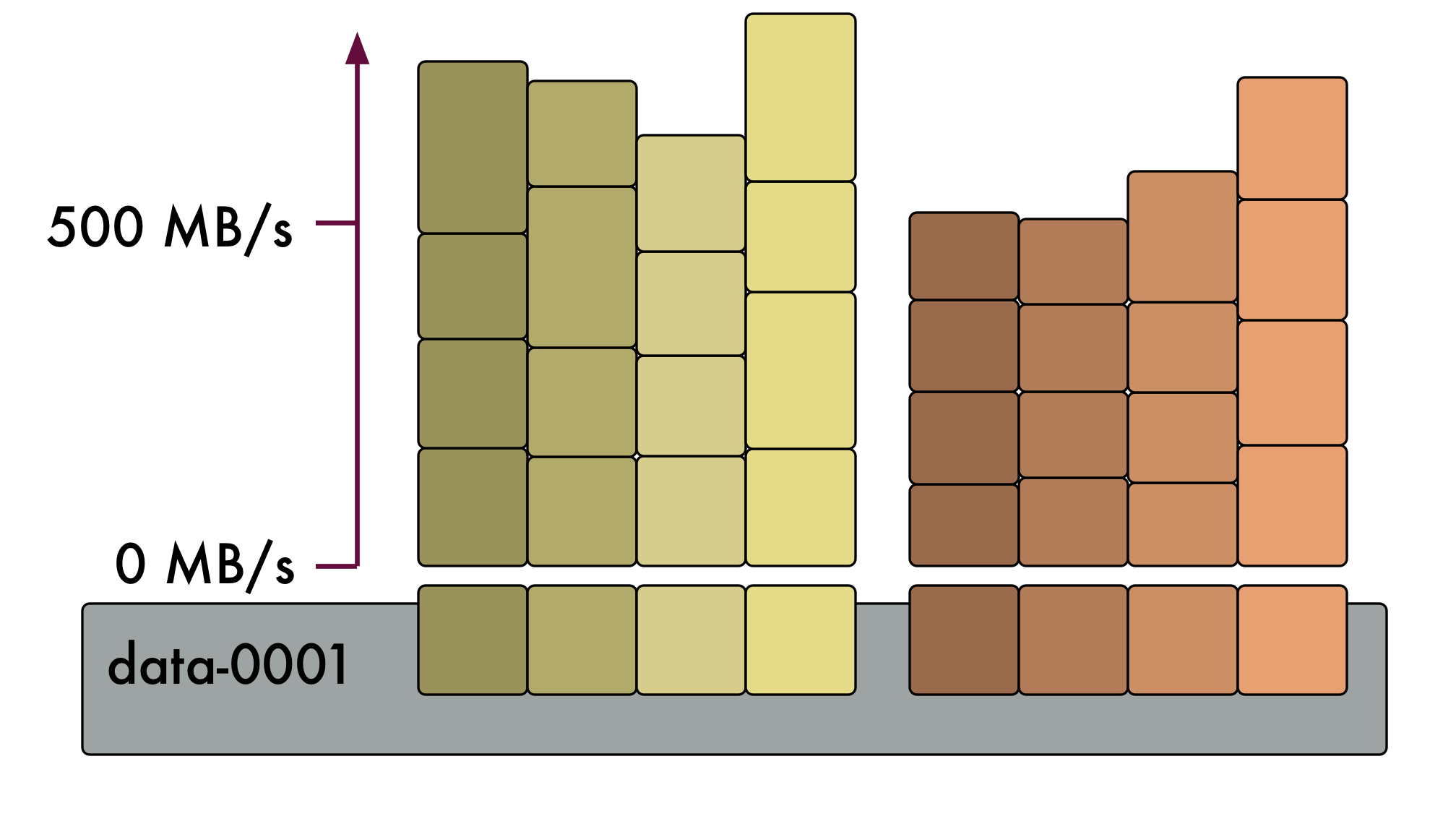
The aggregate I/O read performance achieved by the data server is approximately 5200 MB/s. If we compare the I/O read performance per node with the TCP/IP performance across the ipoib interface, we can see that actually the two are somewhat comparable (within the observed bounds of variability in ipoib performance):
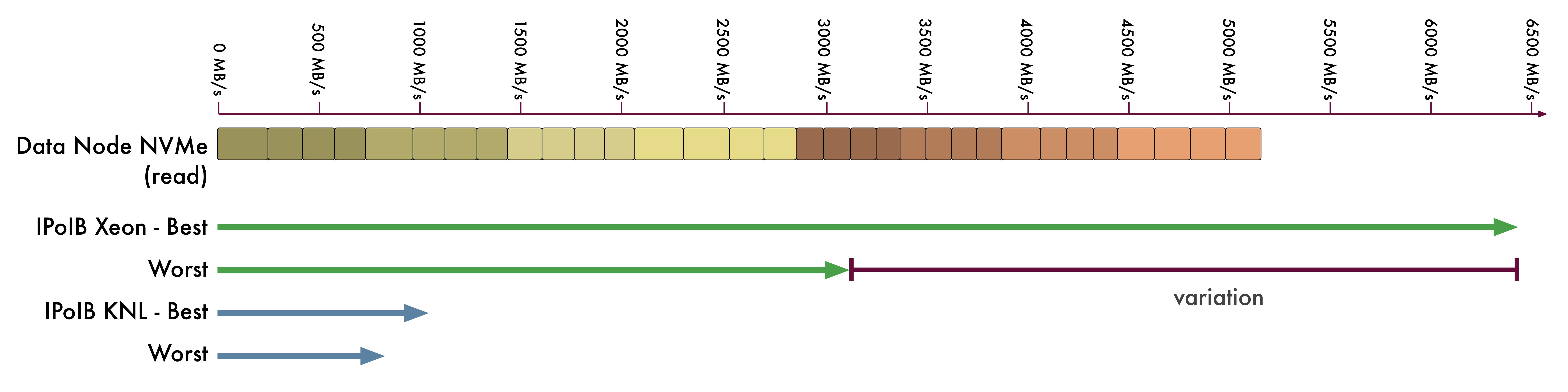
Taking into account that heuristic access patterns are likely to include serving data from the kernel buffer cache taking a sizeable proportion of each data node's 64G RAM, the ipoib network performance is likely to become a bottleneck.
Jewel to Luminous
Preserving the format of the backend data store, the major version of Ceph was upgraded from Jewel to Luminous. Single-client performance was tested using rados bench before and after the upgrade:
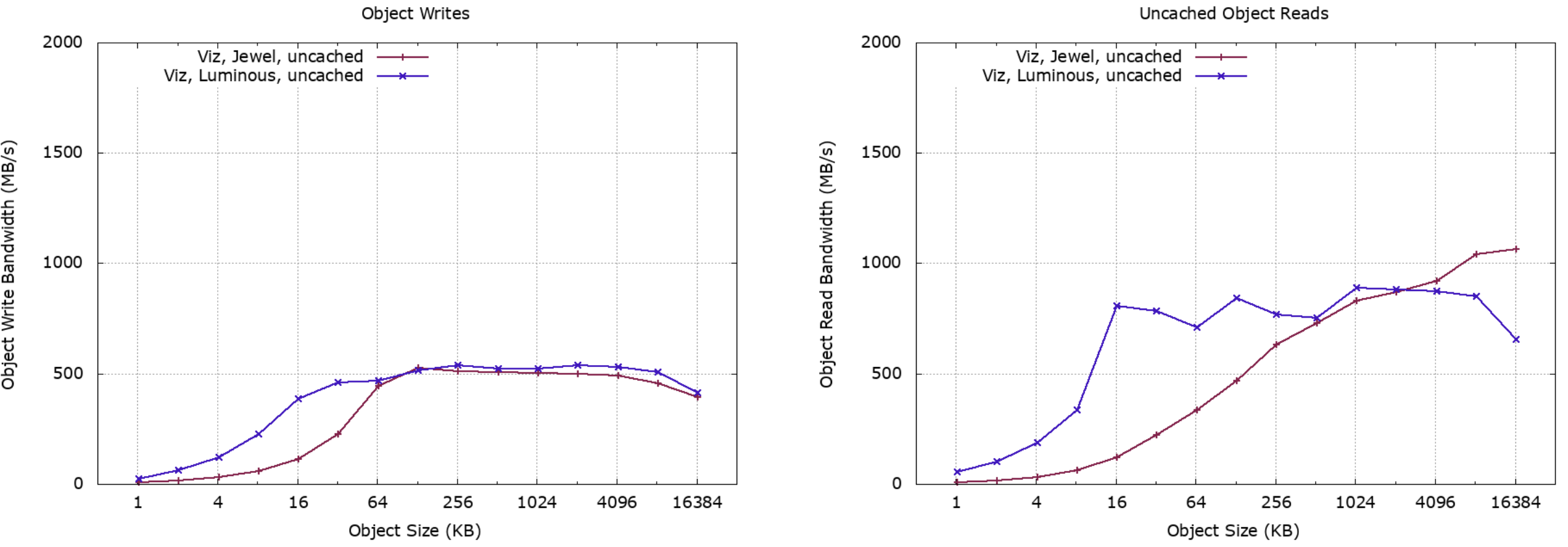
The results that we see indicate a solid improvement for smaller objects (below 64K) but negligible difference otherwise, and no increase in peak performance.
Filestore to Bluestore
The Luminous release of Ceph introduced major improvements in the Bluestore backend data store. The Ceph cluster was migrated to Bluestore and tested again with a single client node and rados bench:
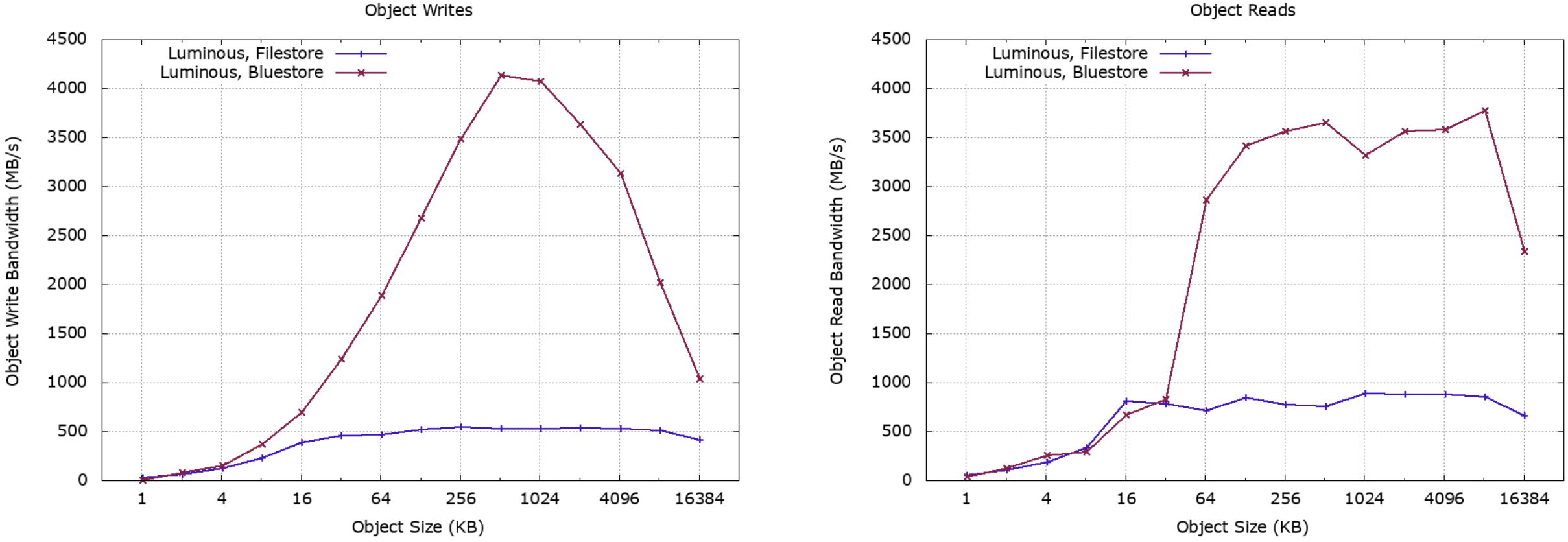
There is a dramatic uplift in performance for larger objects for both reads and writes. The peak RADOS object bandwidth is also within the bounds of the observed limits achieved by the ipoib network interface. This level of performance is becoming less of an I/O problem and more of a networking problem.
That's a remarkable jump. What just happened?
The major differences appear to be the greater efficiency of a bespoke storage back-end over a general-purpose filesystem, and also reduction in the amount of data handling through avoiding writing first to a journal, and then to the main store.
Write Amplification
For every byte written to Ceph via the RADOS protocol, how many bytes are actually written to disk? To find this, we sample disk activity using iostat, aggregate across all devices in the cluster and compare with the periodic bandwidth reports of rados bench. The result is a pair of graphs, plotting RAODS bandwidth against bandwidth of the underlying devices, over time.
Here's the results for the filestore backend:
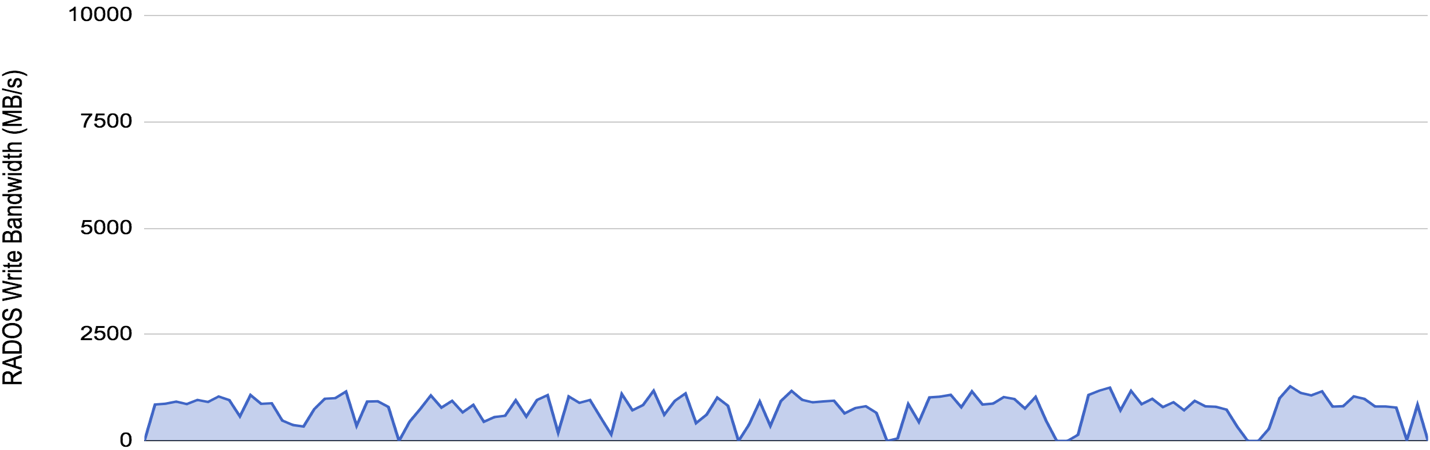
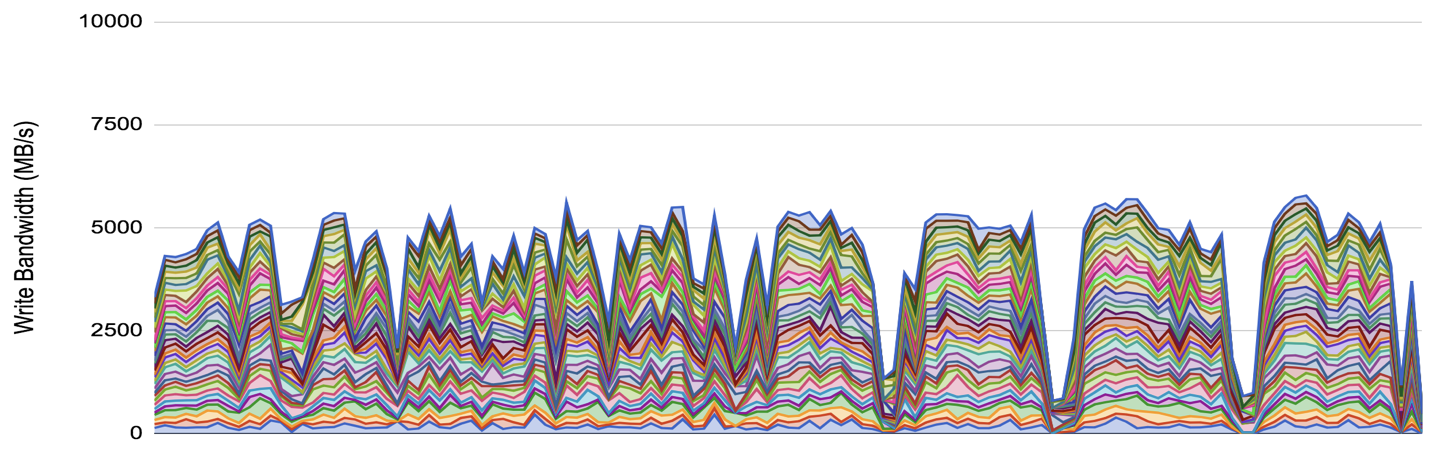
There appears to be a write amplification factor of approx 4.5x - the combination of a 2x replication factor, having every object written first through a collocated write journal, and an small amount of additional overhead for filesystem metadata.
What is interesting to observe is the periodic freezes in activity as the test progresses. These are believed to be the filestore back-end subdividing object store directories when they exceed a given threshold.
Plotted with the same axes, the bluestore configuration is strikingly different:
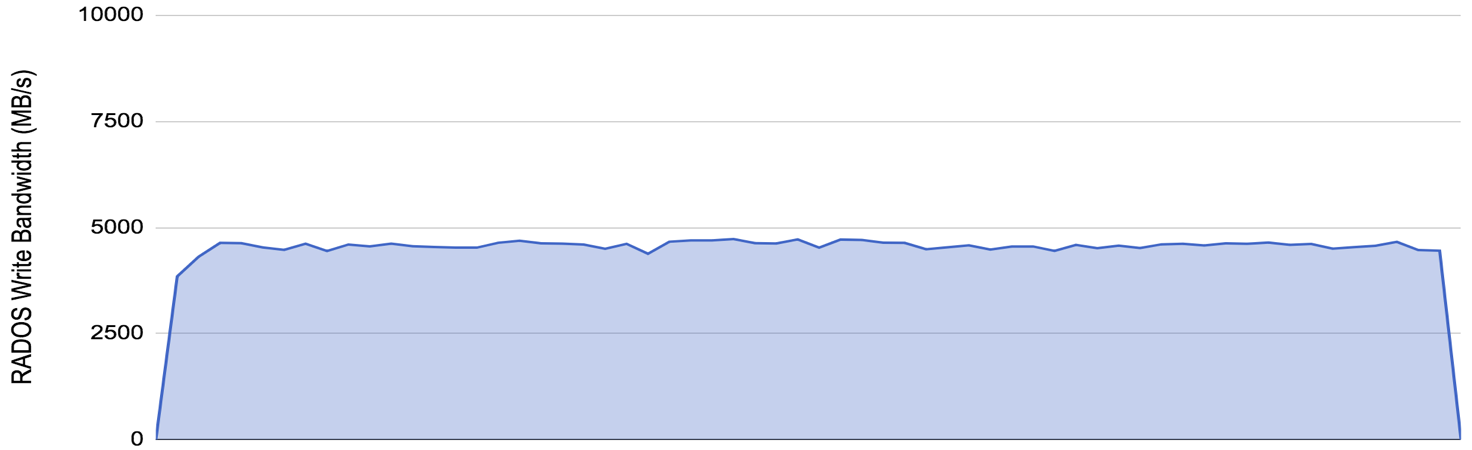
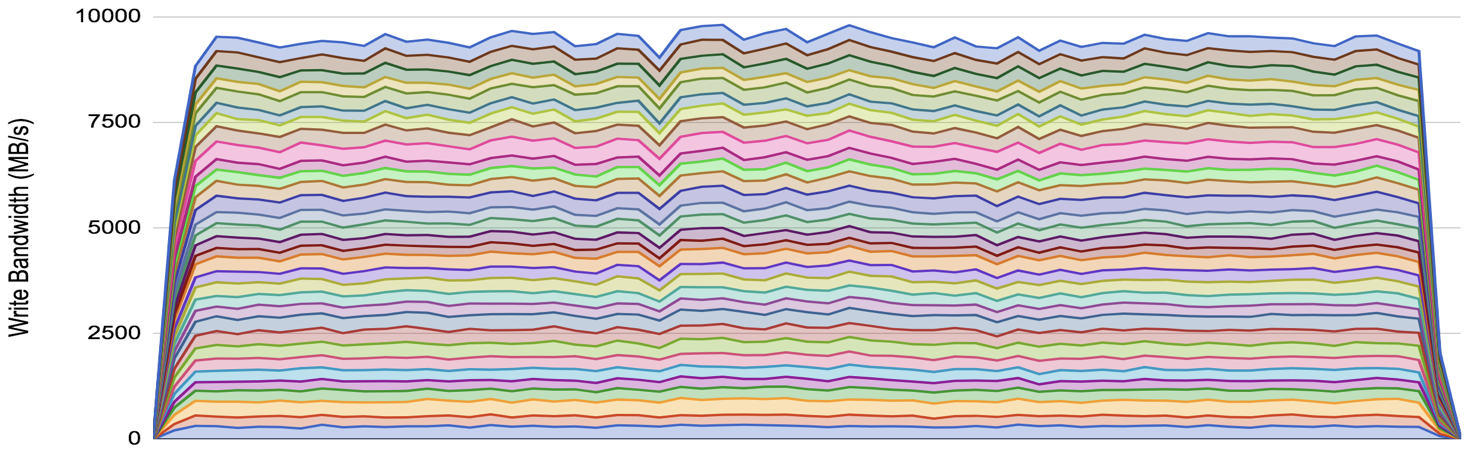
The device I/O performance is approximately doubled, and sustained. The write amplification is reduced from 4.5x to just over 2x (because we are benchmarking here with 2x replication). It is the combination of these factors that give us the dramatic improvement in write performance.
Sustained Write Effects
Using the P3600 devices, performing sustained writes for long periods eventually leads to performance degradation. This can be observed in a halving of device write performance, and erratic and occastionally lengthy commit times.
This effect can be seen in the results of rados bench when plotted over time. In this graph, bandwidth is plotted in green and commit times are impulses in red:
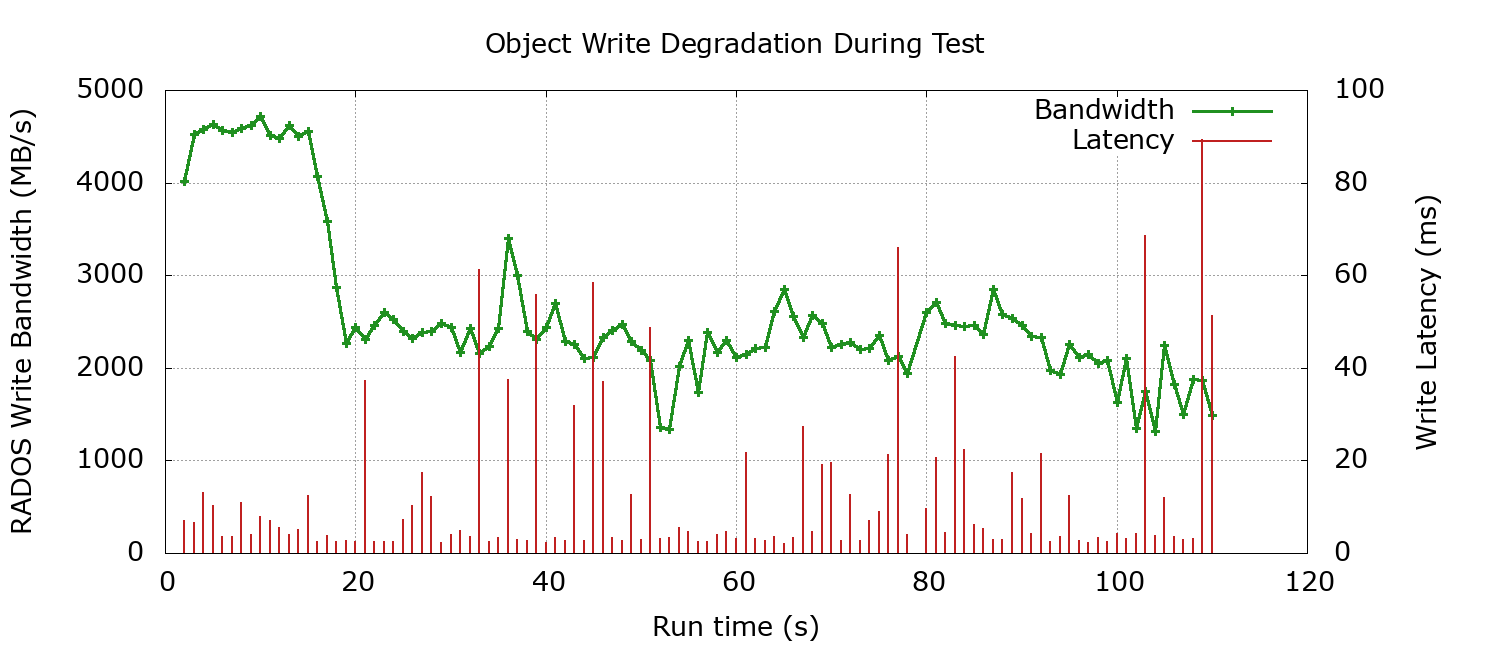
This effect made it very hard to generate repeatable write benchmark results. It was assumed the cause was activity within the NVME controller when the available resource of free blocks became depleted.
Scaling the Client Load
During idle periods on the JULIA system it was possible to harness larger numbers of KNL systems as Ceph benchmark clients. Using concurrent runs of rados bench and aggregating the results, we could get a reasonable idea of Ceph's scalability (within the bounds of the client resources availalbe).
We were able to test with up configurations of to 20 clients at a time:
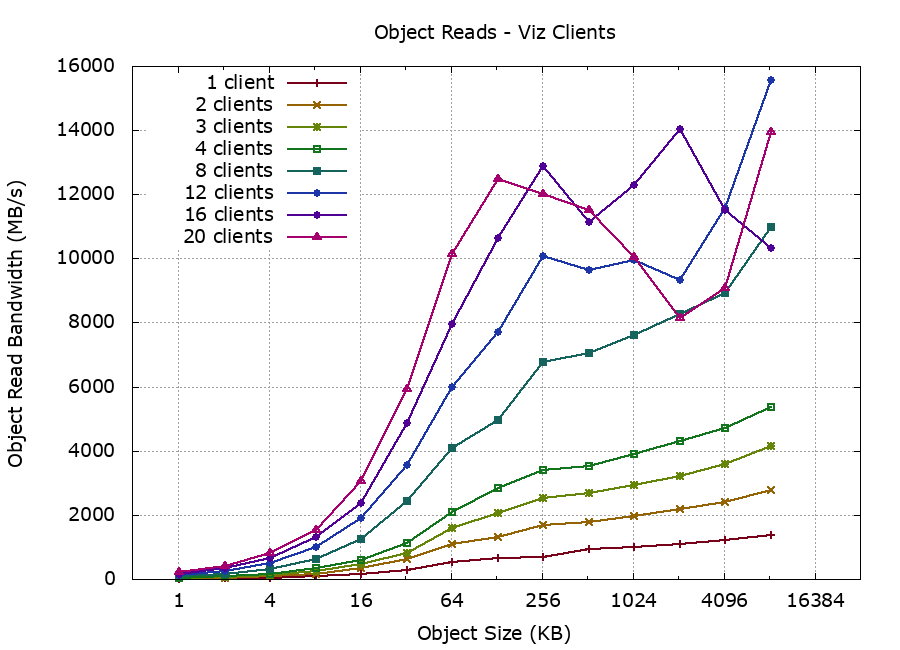
It was interesting to see how the cluster performance became erratic under heavy load and high client concurrency.
The storage cluster BIOS and kernel parameters were reconfigured to a low-latency / high-performance profile, and processor C-states were disabled. This appeared to help with sustaining performance under high load (superimposed here in black):
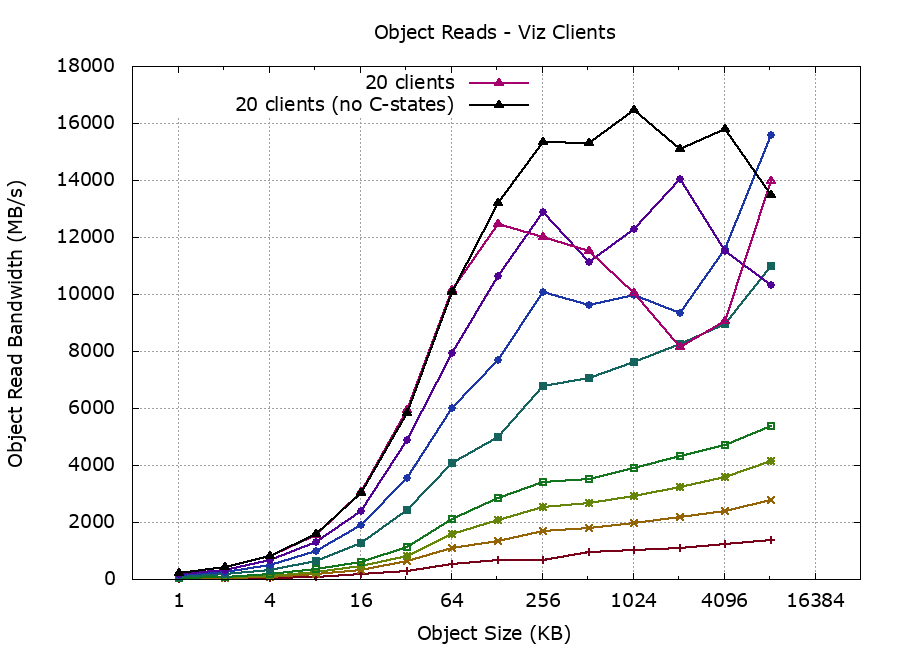
Recalling that the raw I/O read performance of each OSD server was benchmarked at 5200 MB/s, giving an aggregate performance across all four servers of 20.8 GB/s, our peak RADOS read performance of 16.5 GB/s represents about 80% of peak raw performance.
Spectre/Meltdown Strikes
At this point, microcode and kernel mitigations were applied for the Spectre/Meltdown CVEs. After retesting, the raw I/O read performance the aggregate performance per OSD server was found to have dropped by over 15%, from 5200 MB/s to 4400 MB/s. The aggregate raw read performance of the Ceph cluster was now 17.6 GB/s.
Luminous to Mimic
Along with numerous improvements and optimisations, the Mimic release also heralded the deprecation of support for raw partitions for OSD backing, in favour of standardising on LVM volumes.
Using an Ansible Galaxy role, we zapped our cluster and recreated a similar configuration within LVM. We retained the same configuration of four OSDs associated with each physical NVME device. Benchmarking the I/O performance using fio revealed little discernable difference.
We redeployed the cluster using LVM and ceph-ansible and re-ran the rados bench tests. The difference when using Ceph was dramatic for object sizes of 64K and bigger:
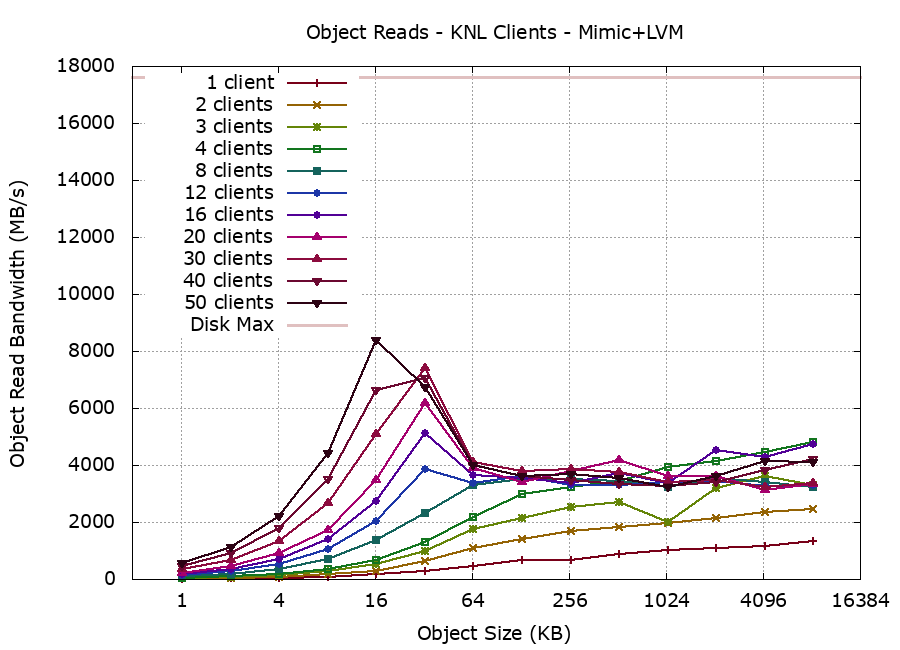
Reprovisioning again with partitions (and ignoring the deprecation warnings) restored and increased levels of performance:
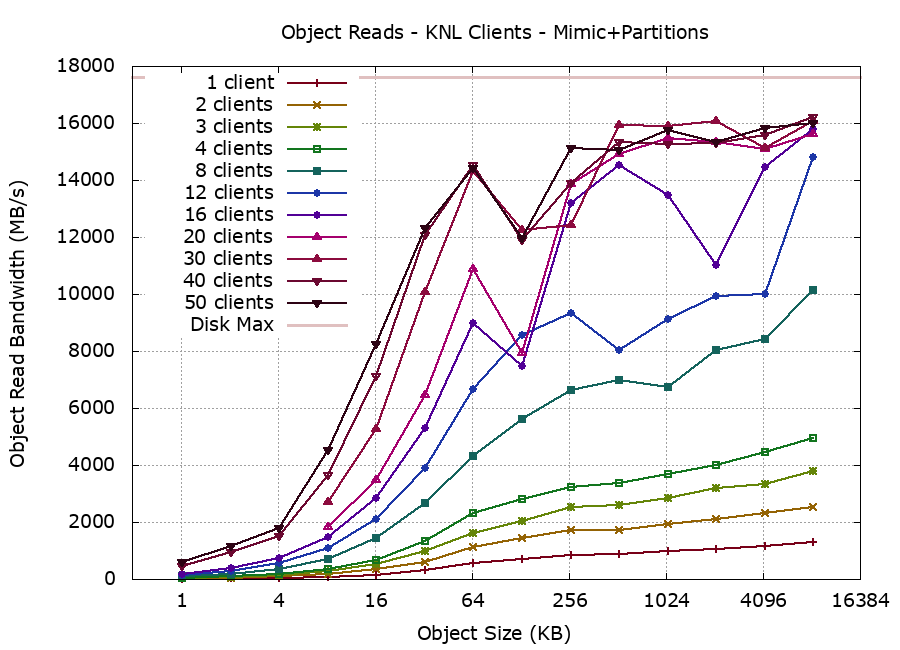
Taking into account the Spectre/Meltdown mitigations, Ceph Mimic is delivering up to 92% efficiency over RADOS protocol.
UPDATE: After presenting these findings at Ceph Day Berlin, Sage Weil introduced me to the Ceph performance team at Red Hat, and in particular Mark Nelson. Mark helped confirm the issue and with analysis on the root cause. It looks likely that Bluestore+LVM suffers the same issue as XFS+LVM on Intel NVMe devices as reported here (Red Hat subscription required). The fix is to ugrade the kernel to the latest available for Red Hat / CentOS systems.
Unfortunately by this time JULIA reached the end of the project lifespan and we were not able to verify this. However, on a different system with a newer hardware configuration, I was able to confirm that the performance issues occur with kernel-3.10.0-862.14.4.el7 and are resolved in kernel-3.10.0-957.1.3.el7.
Native Network Performance for HPC-Enabled Ceph
When profiling the performance of this system using perf and flame graph analysis, I found that under high load 52.5% of the time appeared to be spent in netowrking, either in the Ceph messenger threads, the kernel TCP/IP stack or the low-level device drivers.
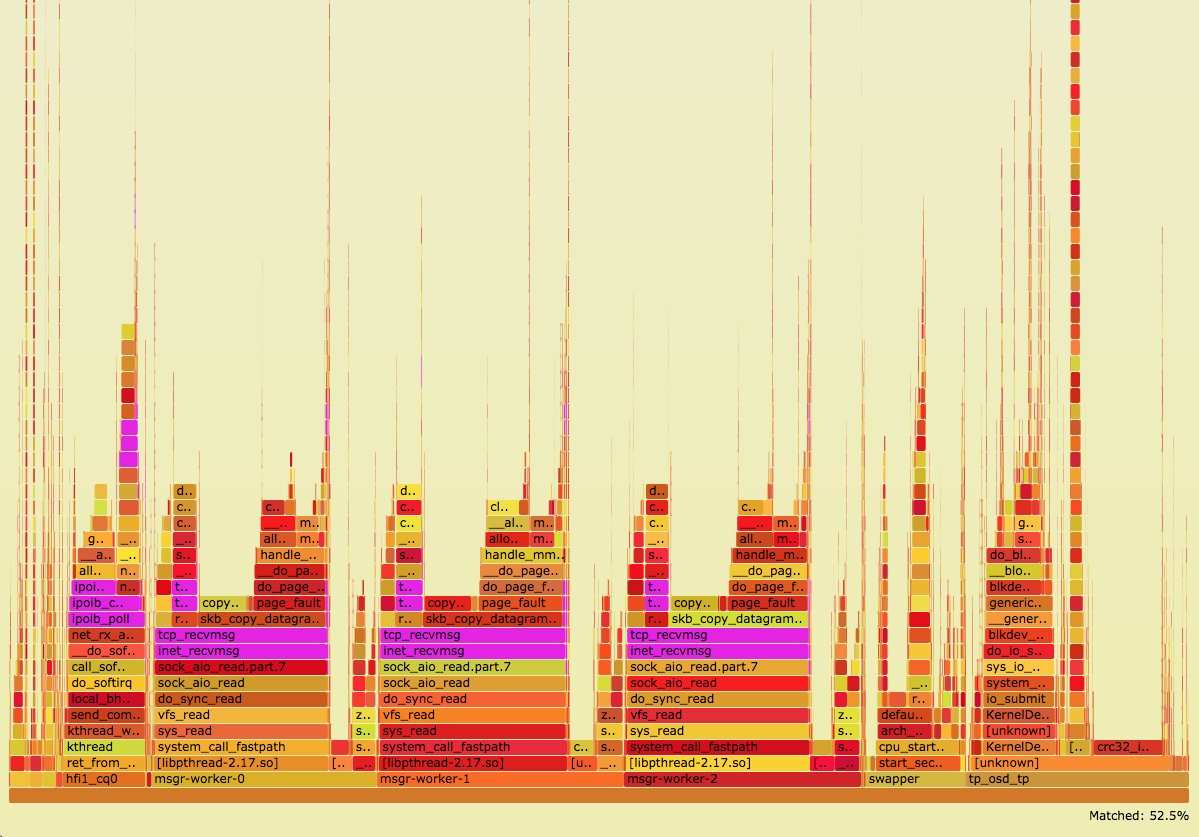
A substantial amount of this time is actually spent in servicing page faults (a side-effect of the Spectre/Meltdown mitigations) when copying socket data between kernel space and user space. This performance data makes a strong case, at least for systems with this balance of compute, storage and networking, for bypassing kernel space, bypassing TCP/IP (with its inescapable copying of data) and moving to a messenger class that offers RDMA.
When the Julia project end was announced, and our users left the system, we upgraded Ceph one final time, from Mimic to master branch.
Ceph, RDMA and OPA
Ceph has included messenger classes for RDMA for some time. However, our previous experience of using these with a range of RDMA-capable network fabrics (RoCE, InfiniBand and now OPA) was that the messenger classes for RDMA work reasonably well for RoCE but not for Infiniband or OPA.
For RDMA support, the systemd unit files for all communicating Ceph processes must have virtual memory page pinning permitted, and access to the devices required for direct communication with the network fabric adapter:
For example, in /usr/lib/systemd/system/ceph-mon@.service, add:
[Service]
LimitMEMLOCK=infinity
PrivateDevices=no
Clients also require support for memory locking, which can be added by inserting the following into /etc/security/limits.conf:
* hard memlock unlimited
* soft memlock unlimited
Fortunately Intel recently contributed support for iWARP (another RDMA-enabled network transport), which is not actually iWARP-specific but does introduce use of a protocol parameter broker known as the RDMA connection manager, which provides greater portability for RDMA connection establishment on a range of different fabrics.
To enable this support in /etc/ceph/ceph.conf (here for the OPA hfi1 NIC):
ms_async_rdma_device_name = hfi1_0
ms_async_rdma_polling_us = 0
ms_async_rdma_type = iwarp
ms_async_rdma_cm = True
ms_type = async+rdma
Using the iWARP RDMA messenger classes (but actually on OPA and InfiniBand) got us a lot further thanks to the connection manager support. However, with OPA the maintenance of cluster membership was irregular and unreliable. Further work is required to iron out these issues, but unfortunately our time on JULIA has completed.
Looking Ahead
The project drew to a close before our work on RDMA could be completed to satisfaction, and it is premature to post results here. I am aware of other people becoming increasingly active in the Ceph RDMA messaging space. In 2019 I hope to see the release of a development project by Mellanox to develop a new RDMA-enabled messenger class based on the UCX communication library. (An equivalent effort to perform the equivalent in libfabric could be even more compelling).
Looking further ahead, the adoption of Scylla's Seastar could potentially become a game-changer for future developments with high-performance hardware-offloaded networking.
For RDMA technologies to be adopted more widely, the biggest barriers appear to be testing and documentation of best practice. If we can, at StackHPC we hope to become more active in these areas through 2019.
Acknowledgements
This work would not have been possible (or been far less informative) without the help and support of a wide group of people:
- Adrian Tate and the team from the Cray EMEA Research Lab
- Dan van der Ster from CERN
- Mark Nelson, Sage Weil and the team from Red Hat
- Lena Oden, Bastian Tweddell and the team from Jülich Supercomputer Centre