For optimal reading, please switch to desktop mode.
This post is the first in a series on HPC networking in OpenStack. In the series we'll discuss StackHPC's current and future work on integrating OpenStack with high performance network technologies. This post sets the scene and the varied networking capabilities of one of our recent OpenStack deployments, the Performance Prototype Platform (P3), built for the Square Kilometre Array (SKA) telescope's Science Data Processor (SDP).
(Not Too) Distant Cousins
There are many similarities between the cloud and HPC worlds, driving the adoption of OpenStack for scientific computing. Viewed from a networking perspective however, HPC clusters and modern cloud infrastructure can seem worlds apart.
OpenStack clouds tend to rely on overlay network technologies such as GRE and VXLAN tunnels to provide separation between tenants. These are often implemented in software, running atop a statically configured physical Ethernet fabric. Conversely, HPC clusters may feature a variety of physical networks, potentially including technologies such as Infiniband and Intel Omnipath Architecture. Low overhead access to these networks is crucial, with applications accessing the network directly in bare metal environments or via SR-IOV in when running in virtual machines. Performance may be further enhanced by using NICs with support for Remote Direct Memory Access (RDMA).
Background: the SKA and its SDP
The SKA is an awe-inspiring project, to which any short description of ours is unlikely to do justice. Here's what the SKA website has to say:
The Square Kilometre Array (SKA) project is an international effort to build the world’s largest radio telescope, with eventually over a square kilometre (one million square metres) of collecting area. The scale of the SKA represents a huge leap forward in both engineering and research & development towards building and delivering a unique instrument, with the detailed design and preparation now well under way. As one of the largest scientific endeavours in history, the SKA will bring together a wealth of the world’s finest scientists, engineers and policy makers to bring the project to fruition.
The SDP Consortium forms part of the SKA project, aiming to build a supercomputer-scale computing facility to process and store the data generated by the SKA telescope. The data ingested by the SDP is expected to exceed the global Internet traffic per day. Phew!

The SKA will use around 3000 dishes, each 15 m in diameter. Credit: SKA Organisation
Performance Prototype Platform: a High Performance Melting Pot
The SDP architecture is still being developed, but is expected to incorporate the concept of a compute island, a scalable unit of compute resources and associated network connectivity. The SDP workloads will be partitioned and scheduled across these compute islands.
During its development, a complex project such as the SDP has many variables and unknowns. For the SDP this includes a variety of workloads and an assortment of new hardware and software technologies which are becoming available.
The Performance Prototype Platform (P3) aims to provide a platform that roughly models a single compute island, and allows SDP engineers to evaluate a number of different technologies against the anticipated workloads. P3 provides a variety of interesting compute, storage and network technologies including GPUs, NVMe memory, SSDs, high speed Ethernet and Infiniband.
OpenStack offers a compelling solution for managing the diverse infrastructure in the P3 system, and StackHPC is proud to have built an OpenStack management plane that allows the SDP team to get the most out of the system. The compute plane is managed as a bare metal compute resource using Ironic. The Magnum and Sahara services allow the SDP team to explore workloads based on container and data processing technologies, taking advantage of the native performance provided by bare metal compute.
How Many Networks?
The P3 system features multiple physical networks with different properties:
- 1GbE out of band management network for BMC management
- 10GbE control and provisioning network for bare metal provisioning, private workload communication and external network access
- 25/100GbE Bulk Data Network (BDN)
- 100Gbit/s EDR Infiniband Low Latency Network (LLN)
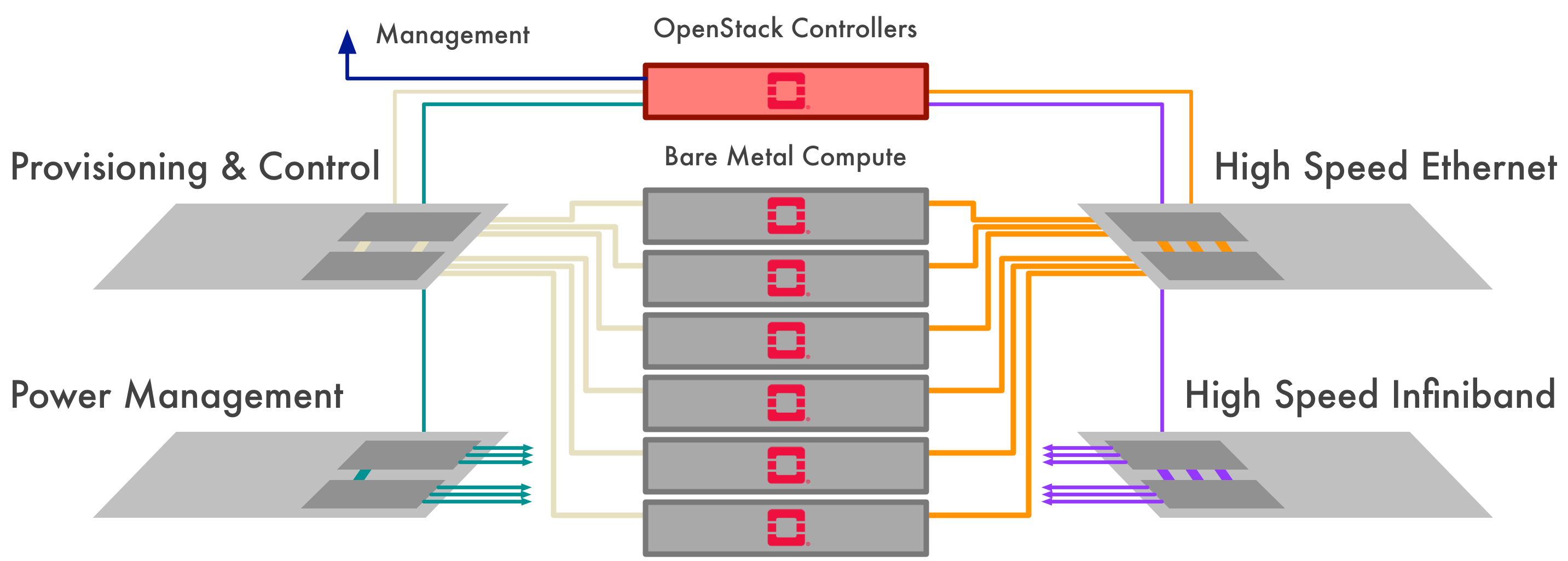
On this physical topology we provision a set of static VLANs for the control plane and external network access, and dynamic VLANS for use by workloads. Neutron manages the control/provisioning network switches, but due to current limitations in ironic it cannot also manage the BDN or LLN, so these are provided as a shared resource.
The complexity of the networking in the P3 system means that automation is crucial to making the system managable. With the help of ansible's network modules, the Kayobe deployment tool is able to configure the physical and virtual networks of the switches and control plane hosts using a declarative YAML format.
Ironic's networking capabilities are improving rapidly, adding features such as multi-tenant network isolation and port groups but still have a way to go to reach parity with VMs. In a later post we'll discuss the work being done upstream in ironic by StackHPC to support multiple physical networks.
Next Time
In the next article in this series we'll discuss how the Kayobe project uses Ansible's network modules to define physical and virtual network infrastructure as code.