For optimal reading, please switch to desktop mode.
Operational Hygiene for Infrastructure as Code
![]()
Rundeck is an infrastructure automation tool, aimed at simplifying and streamlining operational process when it comes to performing a particular task, or ‘job’. That sounds pretty grand, but basically what it boils down to is being able to click a button on a web-page or hit a simple API in order to drive a complex task; For example - something that would otherwise involve SSH’ing into a server, setting up an environment, and then running a command with a specific set of options and parameters which, if you get them wrong, can have catastrophic consequences.
This can be the case with a tool as powerful and all-encompassing as Kayobe. The flexibility and agility of the CLI is wonderful when first configuring an environment, but what about it when it comes to day two operations and business-as-usual (BAU)? How do you ensure that your cloud operators are following the right process when reconfiguring a service? Perhaps you introduced 'run books', but how do you ensure a rigorous degree of consistency to this process? And how do you glue it together with some additional automation? So many questions!
Of course, when you can't answer any or all of these questions, it's difficult to maintain a semblance of 'operational hygiene'. Not having a good handle on whether or not a change is live in an environment, how it's been propagated, or by whom, can leave infrastructure operators in a difficult position. This is especially true when it's a service delivered on a platform as diverse as OpenStack.
Fortunately, there are applications which can help with solving some of these problems - and Rundeck is precisely one of those.
Integrating Kayobe
Kayobe has a rich set of features and options, but often in practice - especially in BAU - there's perhaps only a subset of these options and their associated parameters that are required. For our purposes at StackHPC, we've mostly found those to be confined to:
- Deployment and upgrade of Kayobe and an associated configuration;
- Sync. of version controlled kayobe-config;
- Container image refresh (pull);
- Service deployment, (re)configuration and upgrade.
This isn't an exhaustive list, but these have been the most commonly run jobs with a standard set of options i.e those targetting a particular service. A deployment will eventually end up with a 'library' of jobs in Rundeck that are capable of handling the majority of Kayobe's functionality, but in our case and in the early stages we found it useful to focus on what's immediately required in practical terms, refactoring and refining as we go.
Structure and Usage
Rundeck has no shortage of options when it comes to triggering jobs, including the ability to fire off Ansible playbooks directly - which in some ways makes it a poor facsimile of AWX. Rundeck's power though comes from its flexibility, so having considered the available options, the most obvious solution seemed to be utilising a simple wrapper script around kayobe itself, which would act as the interface between the two - managing the initialisation of the working environment and capable of passing a set of options based on a set of selections presented to the user.
Rundeck allows you to call jobs from other projects, so we started off by creating a library project which contains common jobs that will be referenced elsewhere such as this Kayobe wrapper. The individual jobs themselves then take a set of options and pass these through to our script, with an action that reflects the job's name. This keeps things reasonably modular and is a nod towards DRY principles.
The other thing to consider is the various 'roles' of operators (and I use this in the broadest sense of the term) within a team, or the different hats that people need to wear during the course of their working day. We've found that three roles have been sufficient up until now - the omnipresent administrator, a role for seeding new environments, and a 'read-only' role for BAU.
Finally it's worth mentioning Rundeck's support for concurrency. It's entirely possible to kick off multiple instances of a job at the same time, however this is something to be avoided when implementing workflows based around tools such as Kayobe.
With those building blocks in place we were then able to start to build other jobs around these on a per-project (environment) basis.
Example
Let's run through a quick example, in which I pull in a change that's been merged upstream on GitHub and then reconfigure a service (Horizon).
The first step is to synchronise the version-controlled configuration repository from which Kayobe will deploy our changes. There aren't any user-configurable options for this job (the 'root' path is set by an administrator) so we can just go ahead and run it:
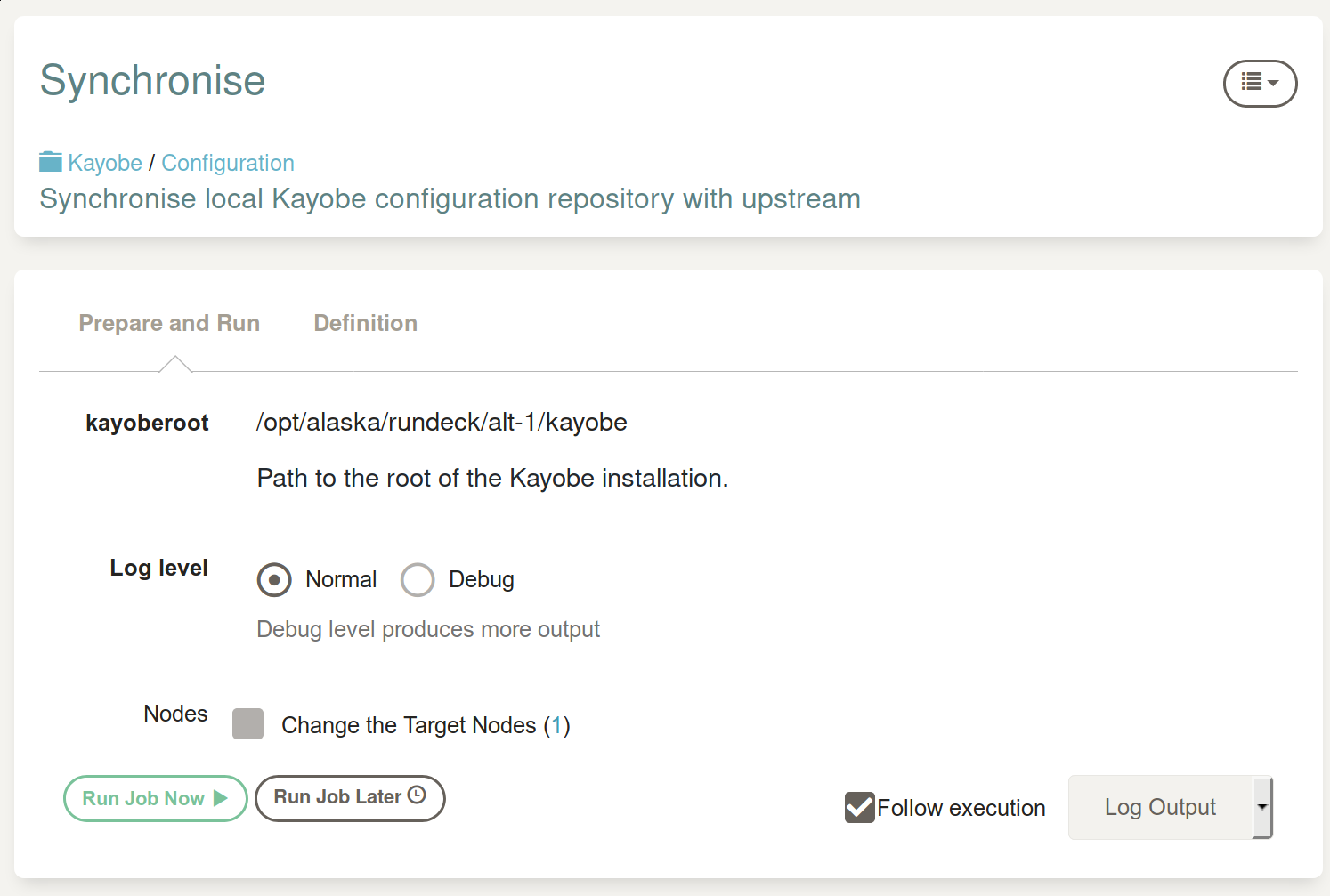
The default here is to 'follow execution' with 'log output', which will echo the (standard) output of the job as it's run:
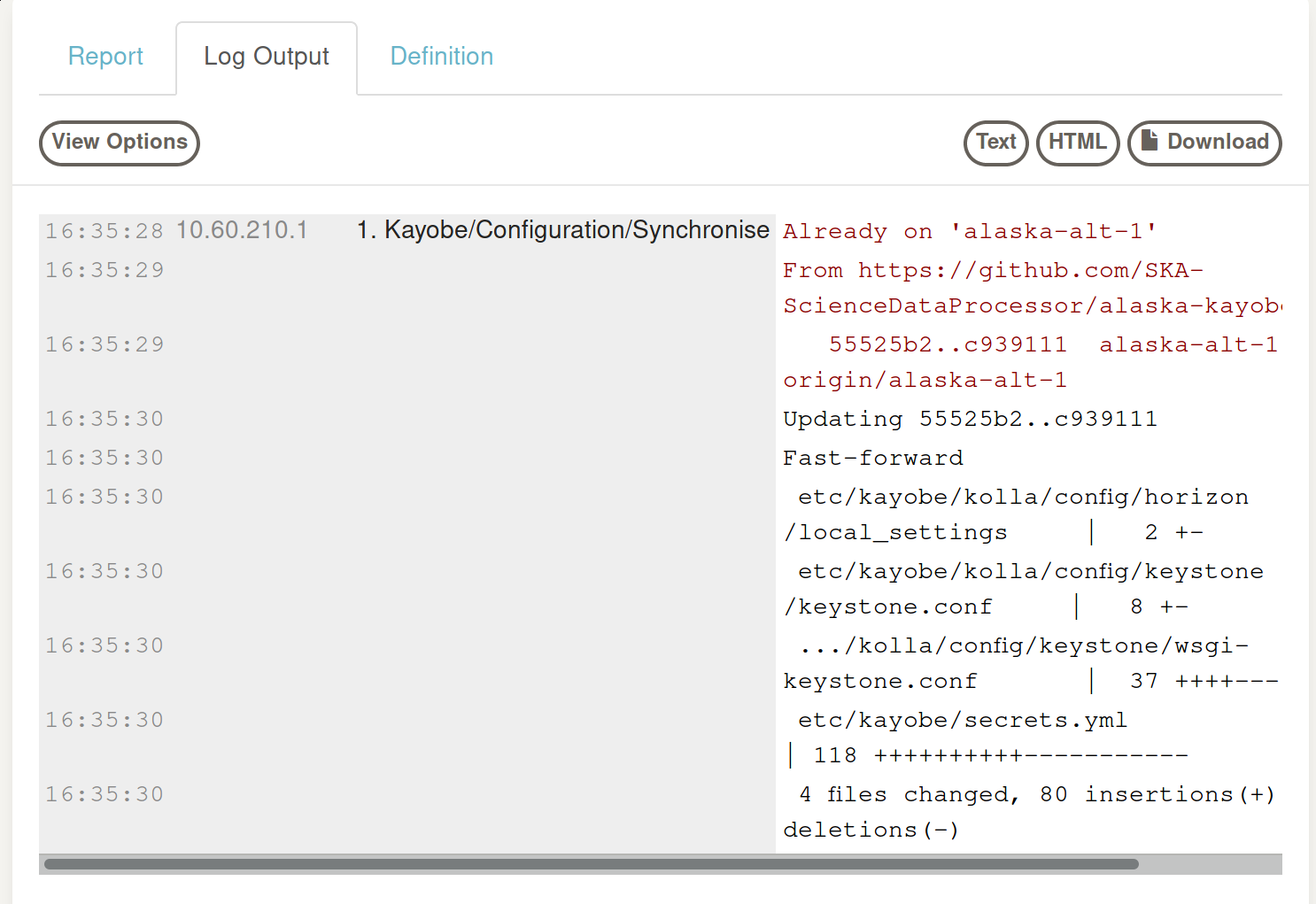
Note that this step could be automated entirely with webhooks that call out to Rundeck to run that job when our pull request has been merged (with the requisite passing tests and approvals).
With the latest configuration in place on my deployment host, I can now go ahead and run the job that will reconfigure Horizon for me:
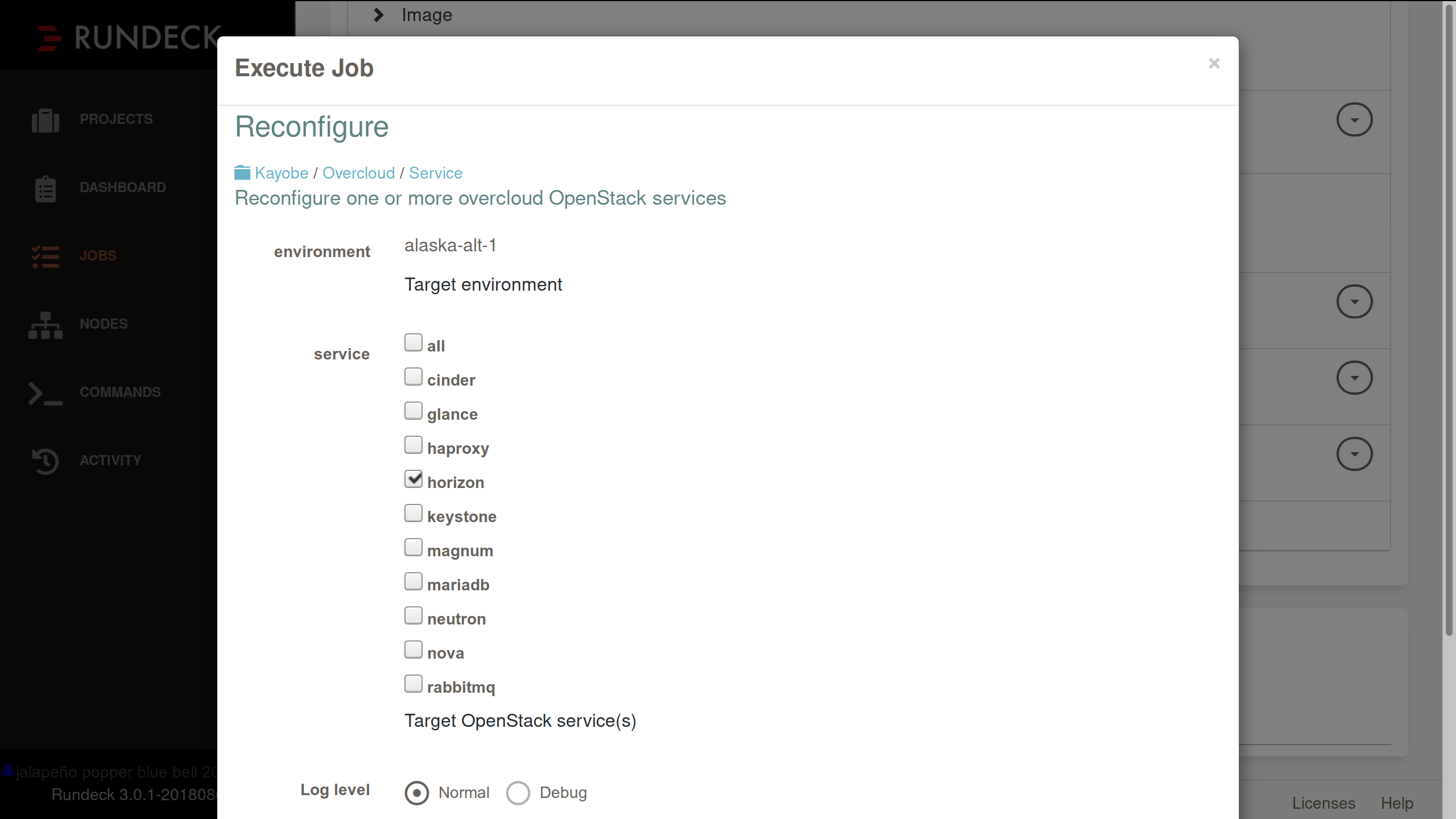
And again, I can watch Kayobe's progress as it's echoed to stdout for the duration of the run:
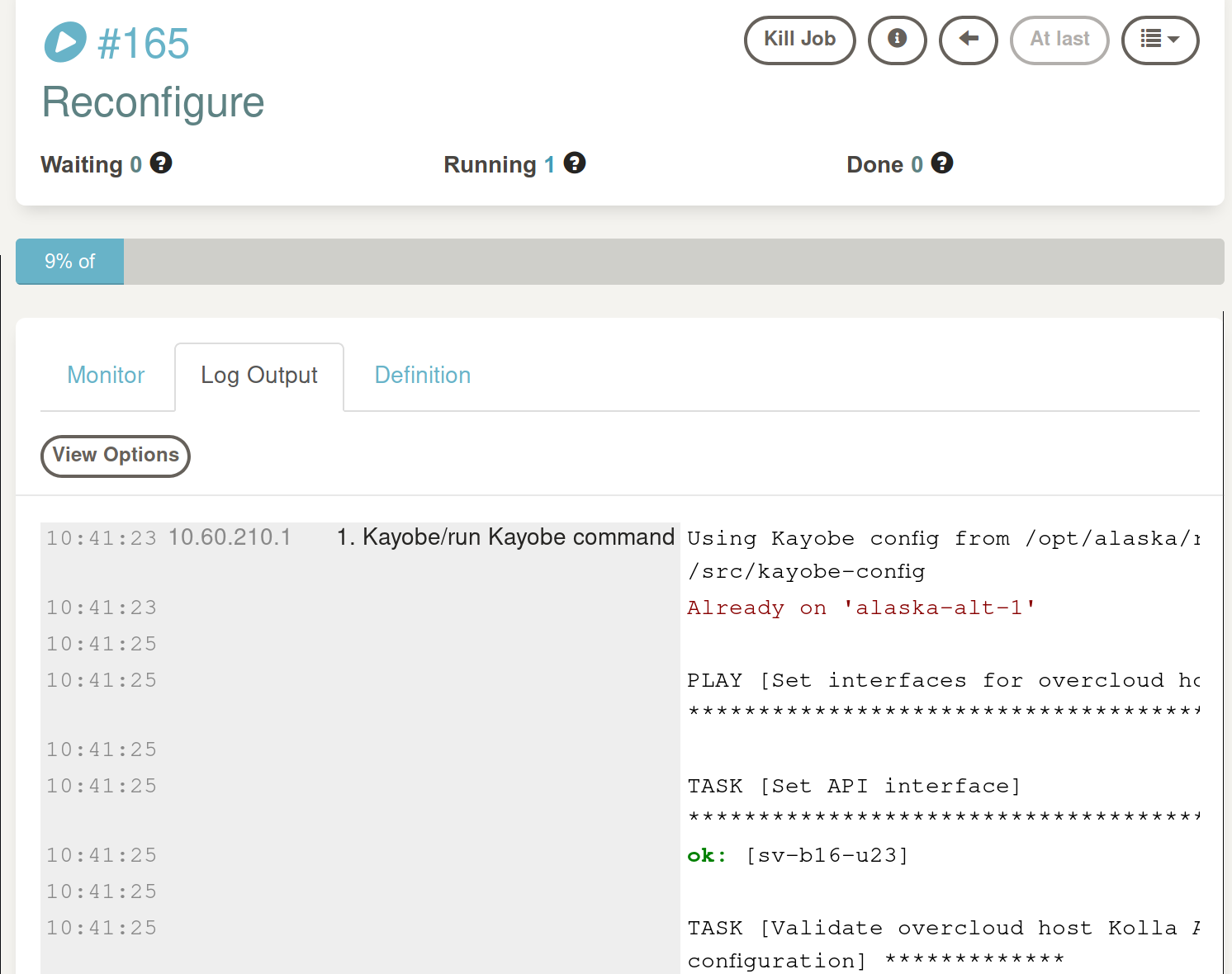
Note that jobs can be aborted, just in case something unintended happens during the process.
Of course, no modern DevOps automation tool would be complete without some kind of Slack integration. In our #rundeck channel we get notifications from every job that's been triggered, along with its status:
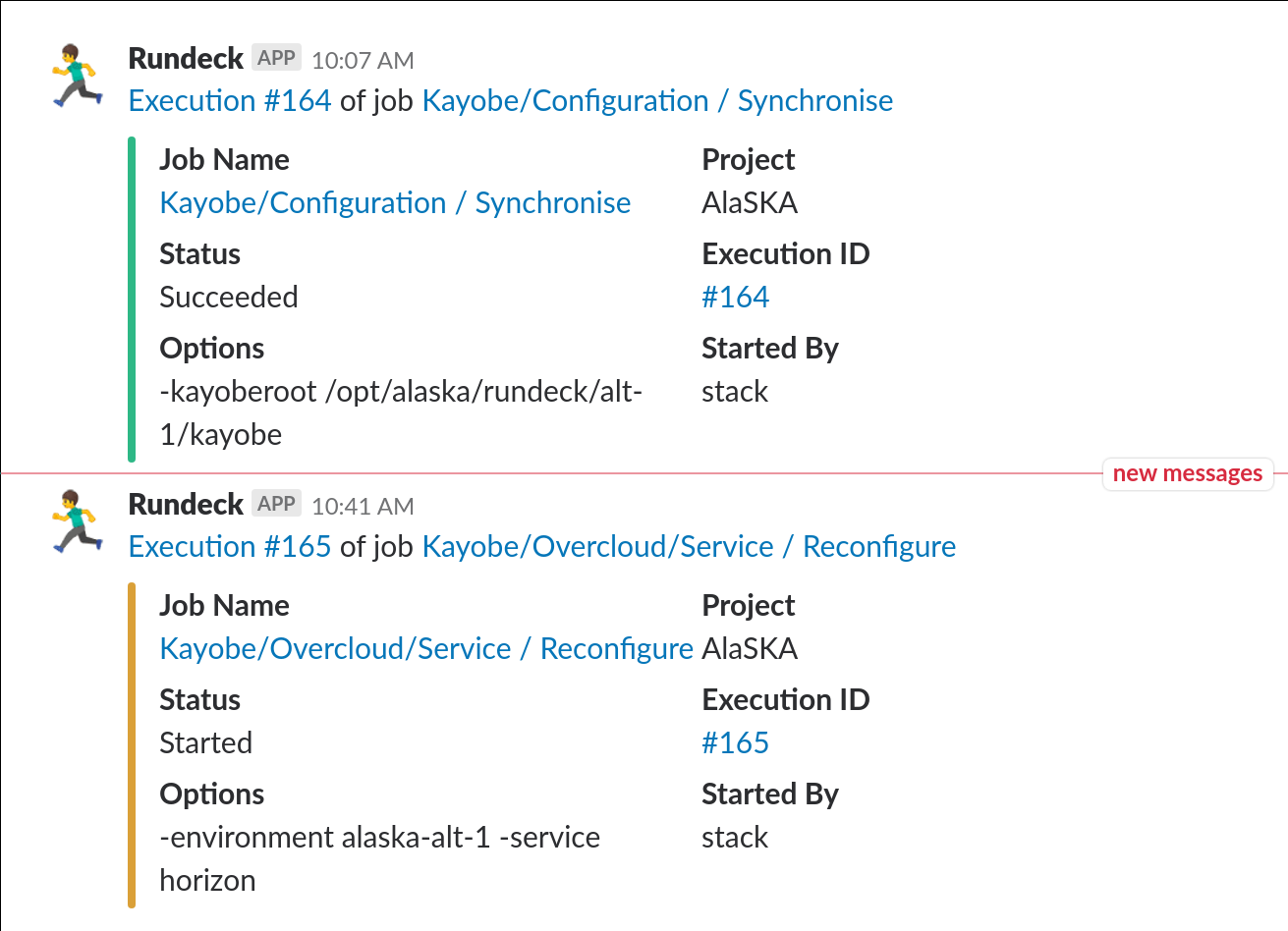
Once the service reconfiguration job has completed, our change is then live in the environment - consistency, visibility and ownership maintained throughout.
CLI
For those with an aversion to using a GUI, as Rundeck has a comprehensive API you'll be happy to learn that you can use a CLI tool in order to interact with it and do all of the above from the comfort of your favourite terminal emulator. Taking the synchronisation job as an example:
[stack@dev-director nick]$ rd jobs list | grep -i sync
2d917313-7d4b-4a4e-8c8f-2096a4a1d6a3 Kayobe/Configuration/Synchronise
[stack@dev-director nick]$ rd run -j Kayobe/Configuration/Synchronise -f
# Found matching job: 2d917313-7d4b-4a4e-8c8f-2096a4a1d6a3 Kayobe/Configuration/Synchronise
# Execution started: [145] 2d917313-7d4b-4a4e-8c8f-2096a4a1d6a3 Kayobe/Configuration/Synchronise <http://10.60.210.1:4440/project/AlaSKA/execution/show/145>
Already on 'alaska-alt-1'
Already up-to-date.
Conclusions and next steps
Even with just a relatively basic operational subset of Kayobe's features being exposed via Rundeck, we've already added a great deal of value to the process around managing OpenStack infrastructure as code. Leveraging Rundeck gives us a central point of focus for how change, no matter how small, is delivered into an environment. This provides immediate answers to those difficult questions posed earlier, such as when a change is made and by whom, all the while streamlining the process and exposing these new operational functions via Rundeck's API, offering further opportunities for integration.
Our plan for now is to try and standardise - at least in principle - our approach to managing OpenStack installations via Kayobe with Rundeck. Although it's already proved useful, further development and testing is required to refine workflow and to expand its scope to cover operational outliers, and on the subject of visibility the next thing on the list for us to integrate is ARA.
If you fancy giving Rundeck a go, getting started is surprisingly easy thanks to the official Docker images as well as some configuration examples. There's also this repository which comprises some of our own customisations, including minor fix for the integration with Ansible.
Kick things off via docker-compose and in a minute or two you'll have a couple of containers, one for Rundeck itself and one for MariaDB:
nick@bluetip:~/src/riab> docker-compose up -d
Starting riab_mariadb_1 ... done
Starting riab_rundeck_1 ... done
nick@bluetip:~/src/riab> docker-compose ps
Name Command State Ports
---------------------------------------------------------------------------------------
riab_mariadb_1 docker-entrypoint.sh mysqld Up 0.0.0.0:3306->3306/tcp
riab_rundeck_1 /opt/boot mariadb /opt/run Up 0.0.0.0:4440->4440/tcp, 4443/tcp
Point your browser at the host where you've deployed these containers and port 4440, and all being well you'll be struck with the login page.
If you would like to get in touch we would love to hear from you. Reach out to
us via Bluesky <https://bsky.app/profile/stackhpc.com>,
LinkedIn <https://www.linkedin.com/company/stackhpc-ltd/> or directly via
our contact page <{filename}/pages/contact.rst>_.