For optimal reading, please switch to desktop mode.
Introduction
The familiarity of OpenStack tooling combined with the power of Kubernetes Cluster API.
That was the motivation behind recent community efforts to develop a new OpenStack Magnum driver combining the Kubernetes Cluster API (CAPI) and Helm projects.
The first official release of the Magnum CAPI Helm driver in June 2024 marked a significant milestone in the process of modernising the Magnum project's Kubernetes offering; however, as with any new technology, there is a learning curve associated with the new concepts and tooling introduced by Cluster API.
This blog post is a follow-on from our previous Magnum article (plus the related presentation at the CERN-hosted OpenInfra Days Europe event) and will provide a more in-depth look at the anatomy of a Magnum CAPI Helm deployment, with a focus on introducing and explaining the relevant concepts which may be less familiar to many OpenStack operators. It is intended as a supplement to the official Magnum CAPI Helm driver documentation.
Prerequisites
The Magnum CAPI Helm driver relies on the core OpenStack components (Keystone, Nova, Neutron, Glance, Cinder) plus the OpenStack Octavia service (for API load balancers) and Barbican service (for cluster certificates) - and, of course, the OpenStack Magnum service. These must be deployed on the target cloud prior to working with the Magnum CAPI Helm driver.
Some level of familiarity with Kubernetes and Helm will also be beneficial.
Core Concepts
Cluster API is a complex and evolving project, and as such, it is not feasible to cover all features and concepts in a single article. Therefore, the remainder of this piece will be dedicated to the aspects of Cluster API that are most relevant to the Magnum CAPI Helm driver. For a more general introduction to Cluster API, see the official documentation or for an overview of the core concepts and CRDs, see here.
The general idea behind the Cluster API project is to provide a Kubernetes-native API for managing the various aspects of cloud infrastructure which together make up a functional Kubernetes cluster. However, this presents an immediate problem, since providing such an interface requires a Kubernetes cluster to exist in the first place... This is where the Cluster API management cluster comes in.
The CAPI management cluster is a standalone Kubernetes cluster which is responsible for providing this Kubernetes-native interface in the form of various Custom Resource Definitions (CRDs).
However, on their own, these CRDs (i.e. custom API endpoints) are somewhat useless (they're essentially just an interface for storing and validating JSON blobs). To make these CRDs useful, we must also add some new Operators (also referred to as controllers) to our CAPI management cluster. These controllers are responsible for watching the relevant Kubernetes Custom Resources for changes and translating the custom resource state into external actions, such as creating cloud resources via OpenStack APIs.
The key CRDs and controllers within a Magnum CAPI Helm management cluster are summarised in the following diagram:
[1]: The addons.stackhpc.com API group will be renamed in the future, as more of the relevant source code repositories are donated by StackHPC to be under the control of an open-governance foundation.
The general purpose of each of the CRDs is as follows:
- clusters.cluster.x-k8s.io: The top-level resource representing a single workload cluster.
- machinedeployment.cluster.x-k8s.io: The Machine equivalent of a Kubernetes pod Deployment.
- machine.cluster.x-k8s.io: A representation of an individual machine (usually a VM) belonging to a workload cluster.
- kubeadmconfigtemplate.cluster.x-k8s.io and kubeadmcontrolplane.cluster.x-k8s.io: Kubeadm is a tool for bootstrapping standard Linux hosts and converting them into Kubernetes cluster nodes. Combined with the relevant controllers, these two CRDs provide a declarative interface for node bootstrapping and configuration.
- openstack{cluster,machinetemplate,machine}.infrastructure.cluster.x-k8s.io: A representation of the OpenStack cloud resources required by a single workload cluster. The cluster-api-provider-openstack (capo-controller-manager in the above diagram) is responsible for reconciling the state of these resources using OpenStack API calls. The cluster-api-janitor also watches these CRDs to clean up any OpenStack resources left behind upon deletion of the workload cluster.
- {helmrelease, manifests}.addons.stackhpc.com: A representation of a Helm release or plain Kubernetes manifest to be installed on a workload cluster. Installation and subsequent reconciliation are carried out by the cluster-api-addon-provider.
Hint: To view a list of the installed CRDs on a given Kubernetes cluster, run kubectl get crds.
Creating a CAPI Management Cluster
Having established that a CAPI management cluster is simply a standard Kubernetes cluster with some additional tooling installed, an obvious follow-on question is: How do we install this extra tooling?
For a basic proof-of-concept setup, we can extract the relevant section from the Magnum CAPI Helm driver's development environment setup script. The highlighted section of this script will do the following:
- Install k3s.
- Install the kubectl, helm, and clusterctl CLI tools.
- Install the various controllers listed in the previous section on the k3s cluster using clusterctl and helm.
Warning: Running the full new-devstack.sh script linked above will also set up an all-in-one devstack environment on the host. This will involve making substantial changes to your system during setup; therefore, the full script should only be used if you intend to do some development work on the driver source code, and if so, should only be run on a dedicated VM that is not used for any other purpose. For setting up a k3s-backed CAPI management cluster, the highlighted section of the script should be extracted and run separately (though ideally still in a dedicated/ephemeral VM).
For advice on setting up a resilient, highly available CAPI management cluster, see later in this article: A Production-Ready CAPI Management Cluster.
Where's all that Magnum stuff gone?
Having set up a working CAPI management cluster, the next step is to configure Magnum and the CAPI Helm driver to make use of this cluster. To do so, the Magnum CAPI Helm driver must be (pip) installed in the same environment (i.e. Python virtual environment or Docker container) as the main Magnum project.
Additionally, the k3s cluster's admin kubeconfig file (found at /etc/rancher/k3s/k3s.yaml in a default k3s installation) must be copied to a location which is visible to the Magnum conductor process. For a Kolla-Ansible (or Kayobe) based OpenStack deployment, the kubeconfig file should be copied into the Magnum config directory on the Ansible control host and Kolla-Ansible will handle the rest. For a more detailed walkthrough of the Magnum CAPI Helm setup process using Kayobe, see this guide.
The final setup consideration from a Magnum perspective is the network topology. The key routes required for a functional Magnum CAPI Helm driver are as follows:
- Routing from the OpenStack control plane - specifically, the Magnum conductor(s) - to the CAPI management cluster.
- Routing from the CAPI management cluster to the OpenStack cloud's external network. Each workload cluster will be created with a load balancer on the external network for the Kubernetes API server; the CAPI management cluster must be able to reach the public IPs of these load balancers.
- Outbound internet access from both the CAPI management cluster and the workload clusters (for pulling container images).
Now that we understand some of the core concepts behind, and key components of, a CAPI management cluster, and having configured Magnum to make use of this CAPI management cluster, we next turn to the user-facing aspects of the setup process.
Reproducible Workload Clusters
To make cluster creation as consistent and reproducible as possible, the Magnum CAPI Helm driver relies on a set of known machine images that are built and tested as part of an upstream CI pipeline. These images are then referenced in Magnum cluster templates.
The aforementioned driver development environment script also contains a section which downloads the latest stable images, uploads them to a target cloud and then creates corresponding cluster templates using the OpenStack CLI. Uploading images and creating templates in this way is sufficient for testing purposes; however, for a production setup, a configuration management solution such as StackHPC's openstack-config repository is recommended. This repository includes an Ansible playbook and some documentation to allow image and cluster template definitions to be placed under version control and easily updated to the latest versions.
Creating a Workload Cluster
Having uploaded the required images to Glance and defined a suitable (set of) cluster template(s), we're finally ready to create some useful workload clusters!
To do so, we first need some OpenStack user credentials along with the required OpenStack CLI client plugins:
source /path/to/openrc.sh
python3 -m venv os-env
source os-env/bin/activate
pip install -U pip
pip install python-openstackclient python-octaviaclient python-magnumclient
Note: An openrc file is required rather than a less-privileged application credential since the cluster creation process involves creating additional user trusts and temporary application credentials for use within Magnum.
The OpenStack CLI can then be used to check which cluster templates are available:
(os-env) ubuntu@demo:~$ openstack coe cluster template list
+--------------------------------------+-------------------------+------+
| uuid | name | tags |
+--------------------------------------+-------------------------+------+
| ac27710b-9ddf-4e6b-b18a-aba204a8c47d | kubernetes-1-27-jammy | None |
| 7eed6e06-81e8-4a5c-af02-31392ef51159 | kubernetes-1-28-jammy | None |
| 562c42fc-7e2c-4926-984d-fb341104fa38 | kubernetes-1-29-jammy | None |
+--------------------------------------+-------------------------+------+
A workload cluster can be created based on one of these templates with
(os-env) ubuntu@demo:~$ openstack coe cluster create \
--cluster-template kubernetes-1-28-jammy \
--master-count 1 --node-count 1 \
demo-cluster
which should return
Request to create cluster <cluster-id> accepted.
and the cluster state can be checked using
(os-env) ubuntu@demo:~$ openstack coe cluster list -c name -c status
+-----------------------+--------------------+
| name | status |
+-----------------------+--------------------+
| demo-cluster | CREATE_IN_PROGRESS |
+-----------------------+--------------------+
After a few minutes, the relevant OpenStack resources (e.g. networks, subnets, load balancers, servers etc.) should start to appear:
(os-env) ubuntu@demo:~$ openstack server list \
--name demo-cluster -c Name -c Status
+-----------------------------------------------+--------+
| Name | Status |
+-----------------------------------------------+--------+
| demo-cluster-ivcsn5ftmi5j-control-plane-24djb | ACTIVE |
+-----------------------------------------------+--------+
and as long as (at least) the first control plane node is active, the kubeconfig for the workload cluster can be obtained with
(os-env) ubuntu@demo:~$ openstack coe cluster config demo-cluster
This command will write the kubeconfig to a file called config in the current working directory, which can then be used with the kubectl CLI tool to interact with the workload cluster:
(os-env) ubuntu@demo:~$ kubectl get nodes --kubeconfig ./config
NAME STATUS ROLES AGE VERSION
demo-cluster-ivcsn5ftmi5j-control-plane-24djb NotReady control-plane 3m11s v1.28.8
Once the creation process is complete, the status field will be updated in the OpenStack cluster list
(os-env) ubuntu@demo:~$ openstack coe cluster list -c name -c status
+-----------------------+-----------------+
| name | status |
+-----------------------+-----------------+
| demo-cluster | CREATE_COMPLETE |
+-----------------------+-----------------+
and all nodes will be registered in the workload cluster
(os-env) ubuntu@scott-test-1:~$ openstack server list --name demo-cluster -c Name -c Status
+------------------------------------------------------+--------+
| Name | Status |
+------------------------------------------------------+--------+
| demo-cluster-ivcsn5ftmi5j-default-worker-cwmhs-h92w7 | ACTIVE |
| demo-cluster-ivcsn5ftmi5j-control-plane-24djb | ACTIVE |
+------------------------------------------------------+--------+
(os-env) ubuntu@demo:~$ kubectl get nodes --kubeconfig ./config
NAME STATUS ROLES AGE VERSION
demo-cluster-ivcsn5ftmi5j-control-plane-24djb Ready control-plane 8m22s v1.28.8
demo-cluster-ivcsn5ftmi5j-default-worker-cwmhs-h92w7 Ready <none> 3m37s v1.28.8
At this point, the workload cluster is ready to use.
Future cluster lifecycle operations, such as adding or removing nodes and performing rolling cluster upgrades, should also be performed via the OpenStack CLI (or tools such as OpenTofu's Magnum provider). See openstack coe -h for a list of available commands and openstack coe <command> -h for detailed information on a specific command.
Wait, what just happened?
The process described above provided a user-centric view of the workload cluster creation process; however, since a functional workload cluster relies on many different parts of an OpenStack cloud, it can be useful for administrators to understand a little more about the inner workings of the Magnum CAPI Helm driver to monitor or troubleshoot the cluster creation process. Non-admin readers who do not have access to their cloud's CAPI management cluster can feel free to skip this section. In the examples below, all commands targetting the CAPI management cluster will be denoted with --kubeconfig capi-mgmt (though in practice the name and location of the management kubeconfig may differ).
When a user submits a cluster creation request via openstack coe cluster create, Magnum core performs some validation on the request and then, based on the properties of the cluster template, hands the cluster creation off to the appropriate Magnum driver by calling its create_cluster function.
When the Magnum CAPI Helm driver receives the cluster creation request, it installs an instance of the openstack-cluster Helm chart onto the CAPI management cluster. The full set of templated Kubernetes manifests created by this Helm release can be viewed using the helm get manifest command. For example, the list of manifests installed as part of the above demo cluster is:
$ helm --kubeconfig capi-mgmt get manifest \
-n magnum-af29bdf3eb4d4467a855f54a0441d9ab demo-cluster-ivcsn5ftmi5j \
| grep ^kind: | uniq -c
1 kind: ServiceAccount
12 kind: Secret
1 kind: Role
1 kind: RoleBinding
1 kind: Deployment
1 kind: Cluster
12 kind: HelmRelease
1 kind: KubeadmConfigTemplate
1 kind: KubeadmControlPlane
1 kind: MachineDeployment
2 kind: MachineHealthCheck
8 kind: Manifests
1 kind: OpenStackCluster
2 kind: OpenStackMachineTemplate
where the Cluster, MachineDeployment, Kubeadm*, OpenStack*, HelmRelease and Manifest resource types are exactly those that were introduced in Core Concepts.
As explained previously, these resource instances alone are not particularly useful. It is the custom controllers which are responsible for acting on these resources to initiate external actions. An example of this can be seen by inspecting the logs for the capo-controller-manager pod, which include messages such as:
$ kubectl --kubeconfig capi-mgmt logs -n capo-system \
capo-controller-manager-544cb69b9d-gjfnf \
| grep demo-cluster | head
I0730 14:27:45.708546 1 openstackcluster_controller.go:262] "Reconciling Cluster" controller="openstackcluster" controllerGroup="infrastructure.cluster.x-k8s.io" controllerKind="OpenStackCluster" OpenStackCluster="magnum-af29bdf3eb4d4467a855f54a0441d9ab/demo-cluster-ivcsn5ftmi5j" namespace="magnum-af29bdf3eb4d4467a855f54a0441d9ab" name="demo-cluster-ivcsn5ftmi5j" reconcileID="2bdca1ff-2fa0-401f-b94e-64ac461adfd4" cluster="demo-cluster-ivcsn5ftmi5j"
I0730 14:27:45.708588 1 openstackcluster_controller.go:432] "Reconciling network components" controller="openstackcluster" controllerGroup="infrastructure.cluster.x-k8s.io" controllerKind="OpenStackCluster" OpenStackCluster="magnum-af29bdf3eb4d4467a855f54a0441d9ab/demo-cluster-ivcsn5ftmi5j" namespace="magnum-af29bdf3eb4d4467a855f54a0441d9ab" name="demo-cluster-ivcsn5ftmi5j" reconcileID="2bdca1ff-2fa0-401f-b94e-64ac461adfd4" cluster="demo-cluster-ivcsn5ftmi5j"
I0730 14:27:45.996274 1 network.go:122] "Reconciling network" controller="openstackcluster" controllerGroup="infrastructure.cluster.x-k8s.io" controllerKind="OpenStackCluster" OpenStackCluster="magnum-af29bdf3eb4d4467a855f54a0441d9ab/demo-cluster-ivcsn5ftmi5j" namespace="magnum-af29bdf3eb4d4467a855f54a0441d9ab" reconcileID="2bdca1ff-2fa0-401f-b94e-64ac461adfd4" cluster="demo-cluster-ivcsn5ftmi5j" name="k8s-clusterapi-cluster-magnum-af29bdf3eb4d4467a855f54a0441d9ab-demo-cluster-ivcsn5ftmi5j"
I0730 14:27:46.986616 1 network.go:202] "Reconciling subnet" controller="openstackcluster" controllerGroup="infrastructure.cluster.x-k8s.io" controllerKind="OpenStackCluster" OpenStackCluster="magnum-af29bdf3eb4d4467a855f54a0441d9ab/demo-cluster-ivcsn5ftmi5j" namespace="magnum-af29bdf3eb4d4467a855f54a0441d9ab" reconcileID="2bdca1ff-2fa0-401f-b94e-64ac461adfd4" cluster="demo-cluster-ivcsn5ftmi5j" name="k8s-clusterapi-cluster-magnum-af29bdf3eb4d4467a855f54a0441d9ab-demo-cluster-ivcsn5ftmi5j"
I0730 14:27:46.986864 1 recorder.go:104] "events: Created network k8s-clusterapi-cluster-magnum-af29bdf3eb4d4467a855f54a0441d9ab-demo-cluster-ivcsn5ftmi5j with id 094e2714-c2c7-4a49-8bbe-1907c7b8dd01" type="Normal" object={"kind":"OpenStackCluster","namespace":"magnum-af29bdf3eb4d4467a855f54a0441d9ab","name":"demo-cluster-ivcsn5ftmi5j","uid":"f78a7f37-01dc-4396-acf1-ba5b0fc0fb5b","apiVersion":"infrastructure.cluster.x-k8s.io/v1alpha7","resourceVersion":"75989071"} reason="Successfulcreatenetwork"
I0730 14:27:47.762945 1 router.go:47] "Reconciling router" controller="openstackcluster" controllerGroup="infrastructure.cluster.x-k8s.io" controllerKind="OpenStackCluster" OpenStackCluster="magnum-af29bdf3eb4d4467a855f54a0441d9ab/demo-cluster-ivcsn5ftmi5j" namespace="magnum-af29bdf3eb4d4467a855f54a0441d9ab" name="demo-cluster-ivcsn5ftmi5j" reconcileID="2bdca1ff-2fa0-401f-b94e-64ac461adfd4" cluster="magnum-af29bdf3eb4d4467a855f54a0441d9ab-demo-cluster-ivcsn5ftmi5j"
which demonstrates the CAPO controller making external API calls to create (some of) the OpenStack resources required by the workload cluster.
The key milestones in between the Magnum CAPI Helm driver performing a helm install of the openstack-cluster chart on the CAPI management cluster and a ready-to-use Magnum workload cluster are:
- The capo-controller-manager creates various OpenStack resources (network, subnet, router, load balancer) along with the first cluster VM.
- The first cluster VM is bootstrapped into a Kubernetes control plane node by the Kubeadm controllers.
- Core cluster services (e.g. a CNI) are installed on the 'cluster' (which at this point consists of a single control plane node). These core services are installed via the cluster-api-addon-provider so their status can be monitored using kubectl get helmrelease -A.
- The cluster creation process will stall until the CNI is ready.
- Once the CNI is up and running, the capo-controller-manager and the kubeadm controllers will create the remaining VMs, bootstrap them as Kubernetes nodes and then add them to the cluster.
- Finally, the remaining cluster add-ons such as the monitoring stack are installed by the cluster-api-addon-provider.
There are various other intermediate steps involved in the cluster creation process aside from these key milestones. The general starting point for understanding the cluster creation process in more detail or troubleshooting a stalled cluster should be the pod logs for each of the custom controllers listed in the Core Concepts section.
Having now covered the concepts behind, and practicalities of, the new Magnum CAPI Helm driver using a simple k3s CAPI management cluster, the next section will provide some guidance on moving towards a more resilient, production-ready deployment.
A Production-Ready CAPI Management Cluster
At StackHPC we have been running CAPI management clusters in production on various OpenStack clouds for the past few years as part of our Azimuth platform. During this time we have learned a thing or two about how to configure and run a reliable management cluster.
This learning has been crystalised in the form of our azimuth-ops Ansible collection and associated azimuth-config repository; the latter of which provides an example environment for deploying a standard CAPI management cluster (as required for Magnum use, rather than the full Azimuth deployment).
When deployed using this Ansible tooling, the Magnum CAPI management cluster is a highly-available, auto-healing Kubernetes cluster which itself is managed by a lightweight k3s cluster (backed by a Cinder volume, for easy backup and recovery). The architecture of the management cluster setup in this scenario looks like:
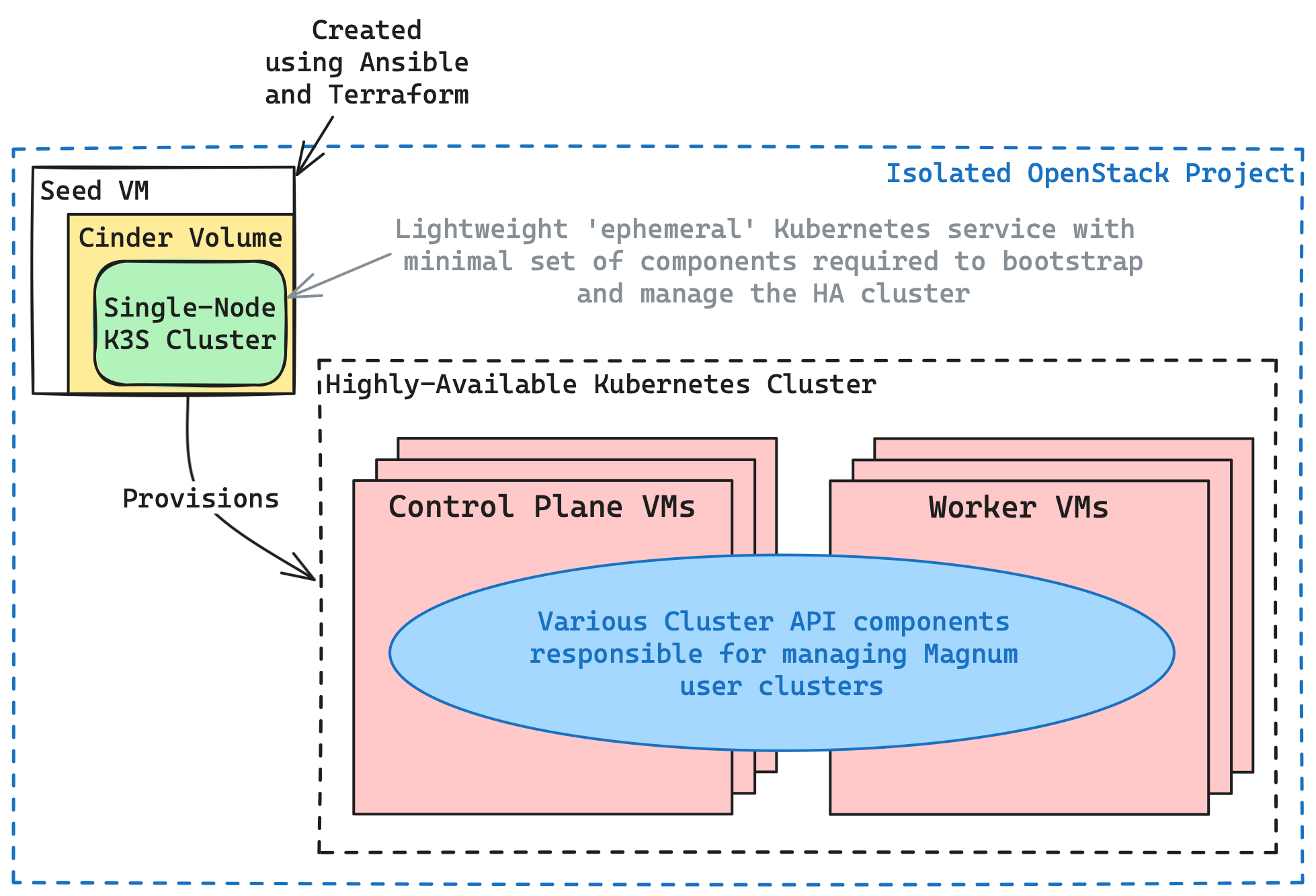
When deployed using this battle-tested Azimuth tooling, a CAPI management cluster benefits from StackHPC's extensive operational experience, as well as the following useful features:
- Version-controlled configuration management and encrypted secrets
- CI/CD automation workflows to simplify routine maintenance and updates.
- Disaster recovery processes that are regularly tested in upstream CI.
- Remote Terraform state storage for the Seed VM.
For now, the canonical source of information for Magnum CAPI management cluster deployments utilising the Azimuth Ansible tooling is the Azimuth Operator Guide. Since this documentation is primarily geared toward Azimuth deployments (rather than a simpler Magnum CAPI management cluster deployment), this information should be supplemented with the Magnum-specific deployment guide in the StackHPC Kayobe Config documentation. In the future, Magnum-specific documentation will be added to the driver's documentation pages.
Conclusion
To summarise, recent developments in the Magnum community involving the Kubernetes Cluster API project have generated significant excitement regarding the future of Magnum's Kubernetes support. In this article, we have introduced the relevant Cluster API concepts and explained how a CAPI management cluster works in tandem with Magnum and its new CAPI Helm driver to create and manage user workload clusters. Finally, we provided an overview of the processes StackHPC use to create resilient and production-ready Magnum CAPI management clusters for our clients' OpenStack clouds.
Get in touch
If you are interested in finding out more about all things OpenStack, Magnum or Cluster API and would like to get in touch, then we would love to hear from you. Reach out to us via X, LinkedIn or directly via our contact page.