For optimal reading, please switch to desktop mode.
Here is a Scientific Computing focused summary of some discussions during the OpenStack Forum. The full list of etherpads is available at: https://wiki.openstack.org/wiki/Forum/Vancouver2018
This blog jumps into the middle of several ongoing conversations with the upstream community. In an attempt to ensure this blog is published while it is still relevant, I have only spent a limited amount of time setting context around each topic. Hopefully it is still a useful collection of ideas from the recent Forum discussions.

As you can see from the pictures the location was great, the discussions were good too...
Role Based Access Control and Quotas
The refresh of OpenStack’s policy system is going well. RBAC in OpenStack is still suffering from a default global admin role and many services allowing access to all but global admin things when you have any role in a given project. Care to define the scope of each API action (system vs project scope) and mapping to one of the three default roles (read-only, member, admin) should help get us to a place where we can add some more interesting defaults.
Hierarchical Quotas discussions were finally more concrete, with a clear path towards making progress. With unified limits largely implemented, agreement was needed on the shape of oslo.limits. The current plan focuses around getting what we hope is the 80% use case working, i.e. when you apply a limit, you have the option of ensuring it also includes any resources used in the tree of projects below. There was an attempt to produce a rule set that would allow for a very efficient implementation, but that has been abandoned as the rule set doesn’t appear to map to many (if any) current use cases. For Nova, it was discussed that the move to using placement to count resources could coincide with a move to oslo.limits, to avoid too many transition periods for operators that make extensive use of quotas.
Preemptible Servers
To understand the context behind preemptible servers, please take a look at the video of a joint presentation I was involved with: Containers on Baremetal and Preemtable VMs at CERN and SKA.
The preemptible servers effort is moving forward, hoping to bring higher utilisation to clouds that use quotas to provide a level of fair sharing of resources. The prototype being built by CERN is progressing well, and Nova changes are being discussed in a spec. There was agreement around using soft shutdown to notify the running instance that its time is up.
The previous nova-spec blocker around the notifications has been resolved. The reaper only wants a subset of the notifications, while at the same time not affecting ceilometer or other similar services. Firstly we agreed to consider the schedule_instances notifications for this purpose, and proposed looking at the routing backend for oslo messaging to ensure the reaper only gets a subset of the notifications.
I personally hope to revisit Blazar once preemptible servers are working. The current future reservation model in Blazar leads to much underutilisation that could be helped by preemptibles. Blazar also seems too disconnected from Nova’s create server API. I do wonder if there is a new workflow making use of the new pending instance status that would feel more cloud native. For example, when a cloud is full, rather than having a reaper to delete instances to make space, maybe you also have a promoter that helps rebuild pending instances as soon as some space becomes free, and maybe says only pick me if all the instances in the group can be built, and you will let me run for at least 8 hours. More thought is required, ideally without building yet another Slurm/HTCondor like batch job scheduler.
Federation
Federation was a big topic of conversation, with the edge computing use cases being heavily discussed. Hallway track conversations covered discussions of the AARC Blueprint Architecture, eduGain Federation Architectures and relating them back to keystone. There is a blog post brewing on the work we at StackHPC have done with STFC IRIS cloud federation project.
The AARC blueprint involving having a “proxy” that provides a single point of management for integrating with multiple external Identity Providers. It uses these IdPs purely for authentication. Firstly allowing for multiple ways of authenticating a single user, and centralising the decisions of what that user is authorized to do, in particular it holds information on what virtual organisations (or communities) that user is associated to, and what roles they have in each organisation. Ideally the task of authorizing users for a particular role is delegated to the manager of that organisation, rather than the operator of the service. When considering the later part of the use case, this application becomes really interesting (thanks to Kristi Nikolla for telling me about it!): https://github.com/CCI-MOC/ksproj
Pulling these ideas together, we get something like this:
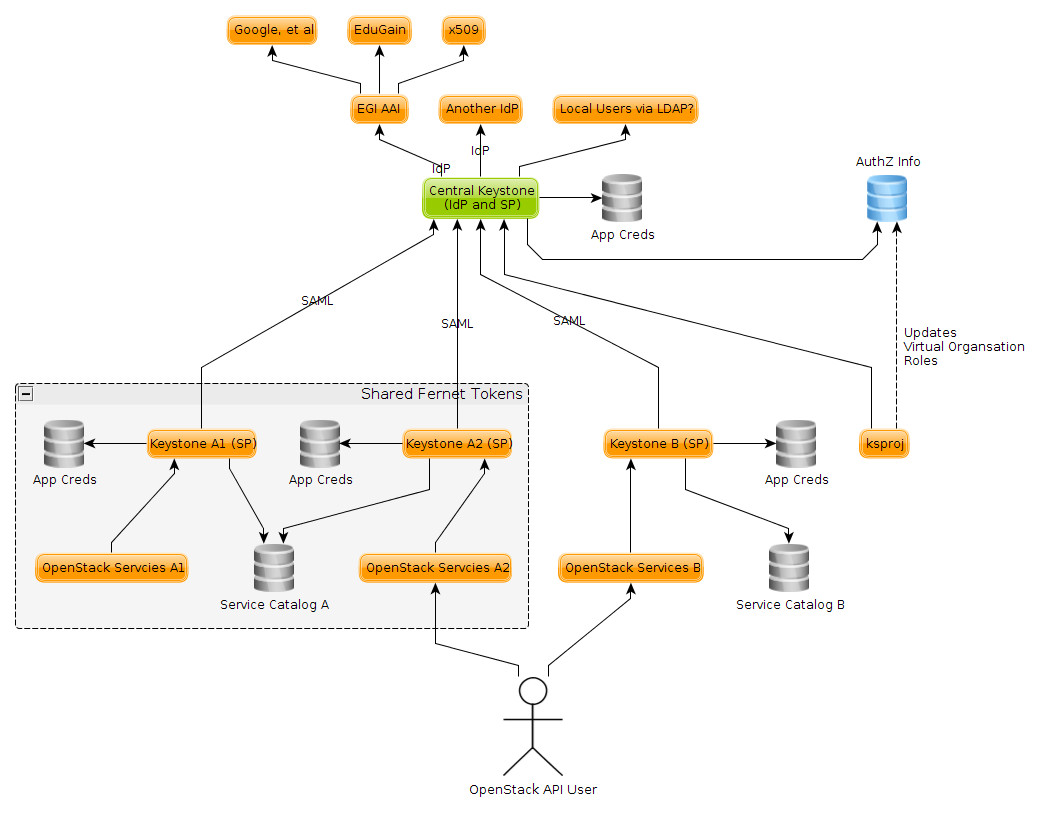
Talking through a few features of the diagram it is worth noting: - Authentication to central Keystone is via an assertion from a trusted Identity Provider, mapped to a local user via federation mapping, such that additional roles can be assigned locally, optionally via ksproj workflows - Authentication to leaf keystone is via assertion from the central keystone, authorization info extracted via locally-stored federation mapping - App Creds are local to each Keystone - There can also be a sharing of keystone tokens, and having all those regions listed in each others service catalog. - There is no nasty long distance sync of keystone databases
It is believed this should work today, but there are some things we could consider changing in keystone: * Federation mappings of groups and projects + roles are inconsistent. One lasts for the life of the keystone token, another lasts forever. One is totally ephemeral, the other is written in the DB. One refreshes the full list of permissions on each authentication, the other can be used to slowly accrue more and more permissions as assertions change over time. For the leaf keystone deployments, a refresh on every authentication, with a time to live applied to the group membership added into the DB. * Note that using groups in the federation maps breaks trusts and application credentials, among other things this breaks Heat and Magnum. Ideally the above federation mapping work ensures all things are written to the database in a way that ensures trusts and application credentials work (see https://bugs.launchpad.net/keystone/+bug/1589993) * Keystone to Keystone federation is fairly non-standard (see http://www.gazlene.net/demystifying-keystone-federation.html) as it is IdP initiated, not the more “normal” SP initiated federation. We should be able to make both configurations possible as we move to SP initiated keystone to keystone federation * No central service catalog, without allowing tokens to work across all those regions. Might be nice to have pointers to service catalogs in the central component (this could be the list of service providers used for keystone to keystone federation, but this seems to not quite fit here).
It turns out, the Edge Computing use cases have very similar needs. Application credentials allow scripts to have a user local to a specific keystone instance, in a way that authentication still works even when the central federation keystone isn’t available.
There is a lot more to this story, and we hope to bring you more blog entries on the details very soon!
Ironic
Lots of usage, including from some of the largest users (looking at you Yahoo/Oath). The effort around extending traits so it gives deploy templates seems really important for lots of people. Of particular interest was the engagement of RedFish developers. In particular, interest around making better use of the TPM and better and more efficient cleaning of a system, including resetting all firmware and configuration.
Kayobe, Kolla and Kolla-Ansible
There seems to be growing usage of kolla containers, in particular triple-o has moved to use them (alongside kolla-ansible). There was talk of more lightweight alternatives to kolla’s containers (as used by openstack-ansible I think), but folks expressed how they liked the current extensibility of the kolla container workflow.
StackHPC makes use of Kayobe, which combines kolla-ansible and bifrost. We discussed how the new kolla-cli built on top of kolla-ansible and used by Oracle’s OpenStack product could be made to work well with kayobe and its configuration patterns. We also spoke a little about how Kayobe is evolving to help deal with different kolla-ansible configurations for different environments (for example production vs pre-production).
Manila
Interesting conversations about CephFS support and usage of Manila from both CERN and RedHat. There was talk about how it is believed that a large public cloud user makes extensive use of Manila, but they were not present to comment on that. Some rough edges were discussed, but the well trodden paths seem to be working well for many users.
Glance and the Image Lifecycle
Glance caching was discussed, largely thinking about Edge Computing use cases, but the solution is more broadly applicable. It was a reminder about how you can deploy additional glance API servers close to the places that want to download, and it will cache images on its local disk using a simple LRU policy. While that is all available today, and I remember working on using that when I worked at Rackspace public cloud, there were some good discussions on how we could add better visibility and control, particularly around pre-seeding the cache with images.
Personally I want to see an OpenStack ecosystem wide way to select “the latest CentOS 7” image. Currently each cloud, or federation of clouds, ends up building their own way of doing things a bit like that. Having helped run a public cloud, the “hard” bit is updating images with security fixes, without breaking people.
This discussion led to the establishing of three key use cases:
Cloud operator free to update “latest” images to include all security fixes, while not breaking:
- By default, list images only shows the “latest” image for each image family
- Users can request the “latest” image for a given family, ideally with the same REST API call across all OpenStack certified clouds
- Users automation scripts request a specific version of an image via image uuid, allowing them to test any new images before having to use them (From a given image the user is consuming, it should be easy to find the new updated image)
- Allow cloud operators to stop users booting new servers from a given image, hiding the image from the list of images, all without breaking existing running instances
In summary, we support (and recommend) this sort of an image lifecycle:
- Cloud operator tests new image in production
- Optional, public beta for new image
- Promote image to new default/latest image for a given image family
- Eventually hide image from default image list, but users can still use and find the image if needed
- Stop users building from a given image, but keep image to not break live migrations
- Finally delete the image, once no existing instances require the image (may never happen).
Things that need doing to make these use cases possible:
- Hidden images spec: https://review.openstack.org/#/c/545397/
- CLI tooling for “image family” metadata, including server side property verification, refstack tests to adopt family usage pattern
- Allow Nova to download a deactivated image, probably using the new service token system that is used by Nova when talking to Neutron and Cinder.
OpenStack Upgrades
It seems there is agreement on how best to collaborate upstream on supporting OpenStack releases for longer, mostly due to agreeing the concept of fast forward upgrades. The backporting policy has been extended to cover these longer lived branches. By the next forum, we will have the first release branch go into extended maintenance, and could have some initial feedback on how well the new system is working.
Kubernetes
Did I put this section in to make my write up more cool? Well no, there is real stuff happening. The OpenStack provider and the community interactions are evolving at quite a pace right now.
Using Keystone for authentication and possibly authorization, looked to be taking shape. I am yet to work out how this fits into the above federation picture, longer term.
When it comes to Nova integration, you can install kubernetes like any other service, Magnum is simply one way you can offer that installation as a service.
Looking at Cinder there are two key scenarios to consider: Firstly consider k8s running inside an OpenStack VM, Secondly consider running k8s on (optionally OpenStack provisioned) baremetal. Given that much work has been done around Cinder, let us consider that case first. When running in a VM, you want to attach the cinder volume to the VM via Nova, but when in baremetal mode (or indeed an install outside of OpenStack all together) you can use cinder to attach the volume inside the OS that is running k8s. The plan is to support both cases, with the latter generally being called “standalone cinder”, focused on k8s deployed outside of OpenStack.
It will be interesting to see how this all interacts with the discussions around natively support multi-tenancy in k8s, including the work on kata-containers (https://blog.jessfraz.com/post/hard-multi-tenancy-in-kubernetes/).
It does seem like many of these approaches are viable, depending on your use case. For me, the current winner is using OpenStack to software define your data centre, and treating the COE as an application that runs on that infrastructure. Magnum is a great attempt at providing that application as a service. Deployment on both Baremetal and VMs makes sense depending on the specific use case involved. More details on how I see some of this currently being used is available in this presentation I was involved with in Vancouver: https://www.openstack.org/videos/vancouver-2018/containers-on-baremetal-and-preemptible-vms-at-cern-and-ska
Cyborg and FPGAs
I am disappointed to not have more to report here. OpenStack now has reasonable GPU and vGPU support, but there appears to be little progress around FPGAs. Sadly it is currently a long way down the list of things I would like to work on.
There was discussion on how the naive PCI passthrough of the FPGA is a bad idea because an attacker would be able to damage the hardware. There does appear to be work on proprietary shells that allow a protected level of access. There was also discussion on how various physical interfaces (such as a network interface, DMA to main memory) will be integrated on the board containing the FPGAs, and how that could be properly integrate with the rest of OpenStack.
There does also appear to be some interest in delivering specific pre-build accelerators build using FPGAs, and some discussion on sharing function contexts and multi-tenancy, but there seemed to be few specifics being shared.
On reflection the ecosystem still seems very vendor specific. As various clouds offer a selection of different services based around FPGAs, it will be interesting to see what approaches gain traction. This is just one example of the possible approaches: https://github.com/aws/aws-fpga/blob/master/hdk/docs/AWS_Shell_Interface_Specification.md
Monitoring and Self-Healing
There are way more interesting sessions than one person can attend, and this section of the update suffers from that. I hope to read many of the other Forum summary blog posts as they start to appear.
Discussing NFV related monitoring and self-healing requirements, it became clear the use cases are very similar to those of some Scientific workloads. Fast detection of problems appeared to be key.
Personally I enjoyed the discussion around high resolution sampling and how it relates to pull (Prometheus) vs push (OpenStack Monasca) style systems. I had forgotten that you can do high resolution sampling processing in a distributed way, i.e. locally on each node (not unlike what mtail can do for logs when using Prometheus). You can then push alarms directly from the node, alongside pulling less time critical messages (i.e. being both a prometheus scrape endpoint and a client to prometheus alert manager). Although it sounds dangerously like an SNMP trap, it seems a useful blend of different approaches.
Scientific SIG
It was great to see the vibrant discussions and lightning talks during the SIG’s sessions. I am even happier seeing those discussion spilling out into all the general Forum sessions thought the week, as I am attempting to document here. For example, it was great to see the overlap between the telco (Edge/NFV/etc) use cases and the scientific use cases.
I was humbled to win the lightning talk prize. If you want to find out more about the data accelerator I am helping build, please take a look at: https://insidehpc.com/2018/04/introducing-cambridge-data-accelerator/
Overall
I feel energized after attending the Forum in Vancouver. I was in lots of Forum sessions that saw real progress made by having engagement from a broad cross section of the community. There was a great combination of new and old voices, all working towards getting real stuff done with OpenStack. I hope the only material change to the Forum, PTG and Ops Summit is to have the events back to back in the same location. I am all for being more efficient, but we must keep the great open collaboration.