For optimal reading, please switch to desktop mode.
Bertie is StackHPC's 2024 summer intern, and has just started a permanent position with the engineering team. This blog post presents a one week investigation he made into configuring RoCE-enabled OpenMPI tasks.
Remote Direct Memory Access (RDMA) is the cornerstone of networking for HPC workloads. RDMA circumvents processor and OS overheads; it enables more direct data exchange by implementing a transport protocol in the Network Interface Card (NIC). InfiniBand (IB) held sway for many years as the primary RDMA enabling standard, delivering very high bandwidth and very low latencies for many in the TOP500. We have demonstrated previously that in recent years modern Ethernet stacks have begun to support RDMA, coming close to the ~1 µs latencies of IB.
Though slightly behind IB in latency performance, RDMA over Converged Ethernet (RoCE) has a number of other significant benefits over IB. The ubiquity of Ethernet is the primary selling point, as existing infrastructure can be leveraged to enable RDMA at lower cost. The overall system complexity and network management is simplified because a single data transport unifies RDMA and conventional IP traffic.
While RoCE is certainly very attractive, as always there are hurdles to trip over when actually putting it to work. The ever-changing networking hardware ecosystem meant OpenMPI has had to adapt. This can lead to some difficult pitfalls to debug yourself out of if not paying close attention to how OpenMPI is configured; that is the focus of this blog post.
Case Study - RoCE vs TCP
During a task of investigating RoCE performance, we happened across some very peculiar behaviour during a simple OpenMPI PingPong benchmark. To set the scene we have two Ethernet network devices:
- eth0
- eth1
These interfaces are used for general network communication using the standard TCP protocol. However, eth1 provides a link layer to a mellanox device; this interface is configured to support RoCE. We can see these available devices by running ip a for the ip interfaces, and ibv_devinfo to show host channel adaptor info for the Mellanox NICs,
hca_id: mlx5_0
transport: InfiniBand (0)
fw_ver: 20.36.1010
node_guid: fa16:3eff:fe4f:f5e9
sys_image_guid: 0c42:a103:0003:5d82
vendor_id: 0x02c9
vendor_part_id: 4124
hw_ver: 0x0
board_id: MT_0000000224
phys_port_cnt: 1
port: 1
state: PORT_ACTIVE (4)
max_mtu: 4096 (5)
active_mtu: 1024 (3)
sm_lid: 0
port_lid: 0
port_lmc: 0x00
link_layer: Ethernet
Initial PingPong results
| PingPong Latency (µs) | PingPong Bandwidth (Mb/sec) |
|---|---|
| 1.62 | 45626.88 |
The default performance of PingPong, with a latency of ~1.6 µs indicates that Open MPI is utilising RoCE as standard. This can be further highlighted in Grafana:
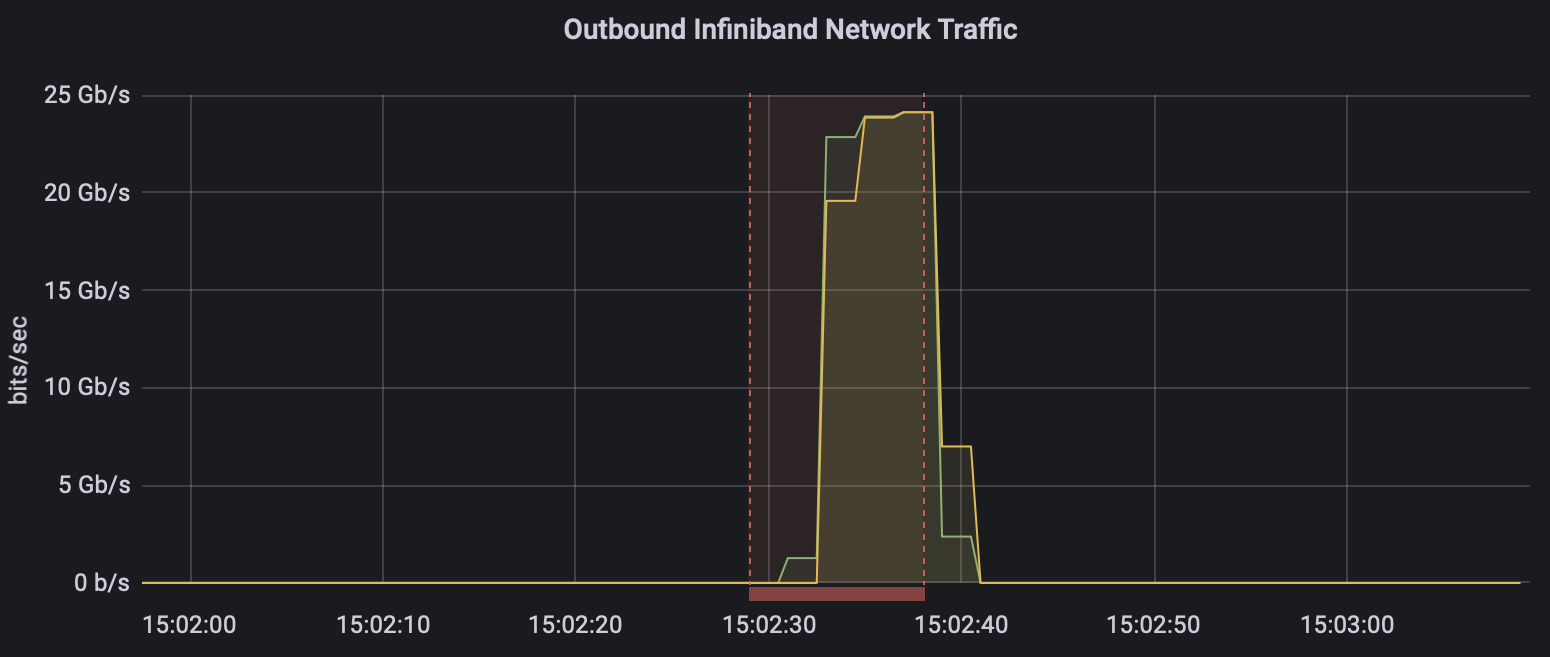
Above shows InfiniBand traffic between two compute nodes. Yellow indicates compute node 0, green indicates compute node 1.
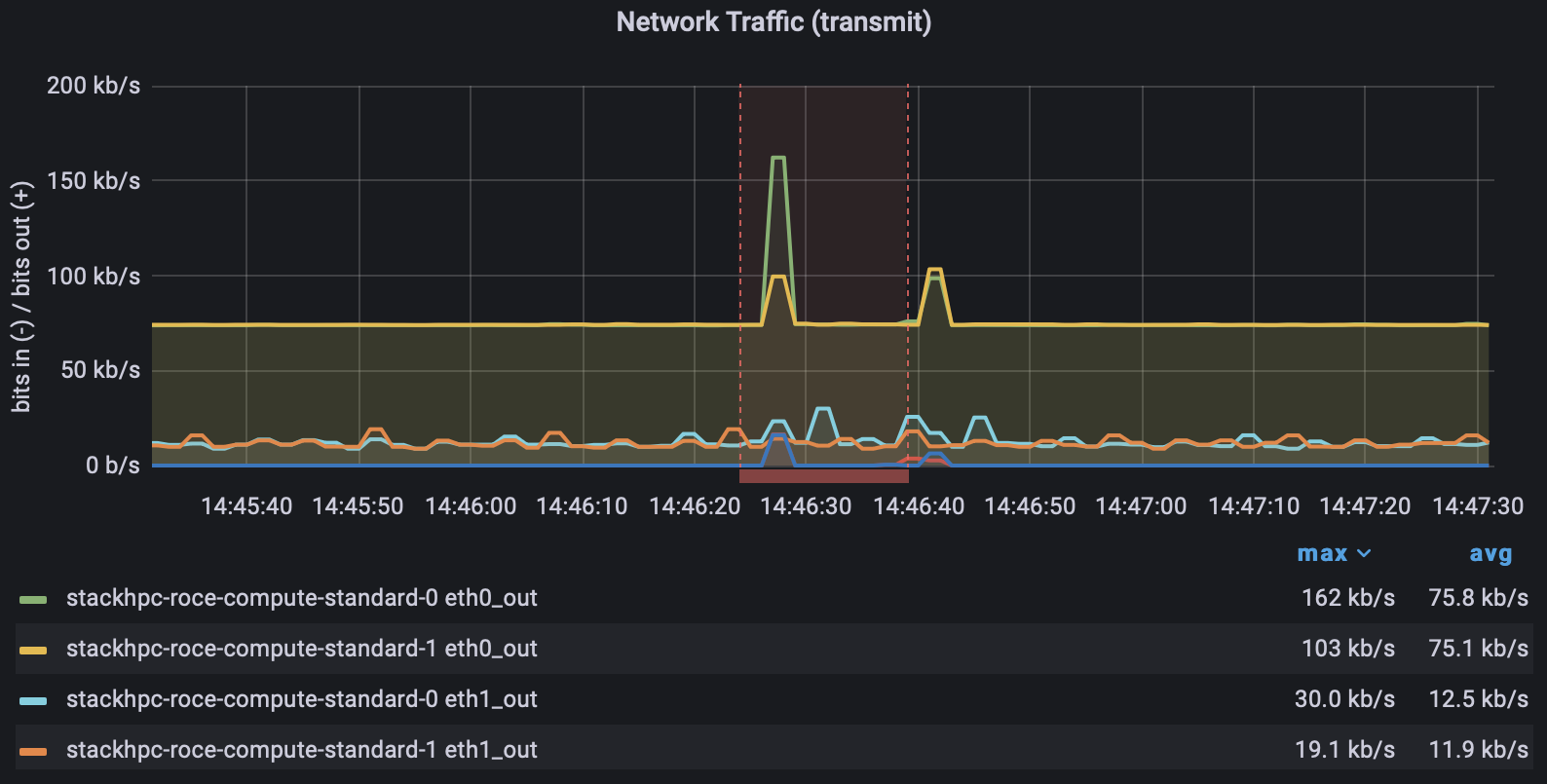
As can be seen above, the network traffic predominately goes over the RDMA device with minimal traffic over TCP (note that our Grafana dashboard refers to this traffic as IB, but in our case it is actually RoCE). At least for TCP interfaces, OpenMPI's default behaviour is to use all available devices on the machine, and selects best ones based on performance characteristics (bandwidth, latency, NUMA locality, etc). In most situations this would be ideal; if you’re investing in RDMA capable infrastructure, you’d want it fully utilised.
Specifying network devices - Very strange behaviour
However, now suppose we want to have finer-grained control over the network devices used for each task. OpenMPI recommends using the Unified Communications X (UCX) library directly, a middleware layer that abstracts the complexities of different communication protocols and hardware. With multiple interfaces, by default UCX uses the first two interfaces in proportion to their detected speed ratio. How this interacts with OpenMPI's default behaviour with multiple interfaces is not clear from documentation. UCX's default behaviour can be overridden by setting UCX_NET_DEVICES to to specify which device is used. For completeness let’s
export UCX_NET_DEVICES=mlx5_0:1
This is the RoCE device we are aiming to utilise linklayered with eth1, giving us:
| PingPong Latency (µs) | PingPong Bandwidth (Mb/sec) |
|---|---|
| 1.59 | 45612.64 |
These results seem to be consistent with what we expect; the very low latency approaches 1 µs, and by selecting the Mellanox NIC directly, it further proves that the previous mpirun above makes full use of the RoCE device as default. Now lets try using just one of the Ethernet devices over TCP. Setting UCX_NET_DEVICES to eth0 gives us the following results:
| PingPong Latency (µs) | PingPong Bandwidth (Mb/sec) |
|---|---|
| 2.14 | 45649.52 |
A latency of ~2.1 µs, though higher than the previous 1.6, is far lower than is possible with TCP/IP networking. The results are plainly not right; we are still getting RDMA latencies even though we're telling UCX to just send over TCP. To prove this is the case, without a shadow of a doubt, we simply need to look at the prometheus scraped data on Grafana again:
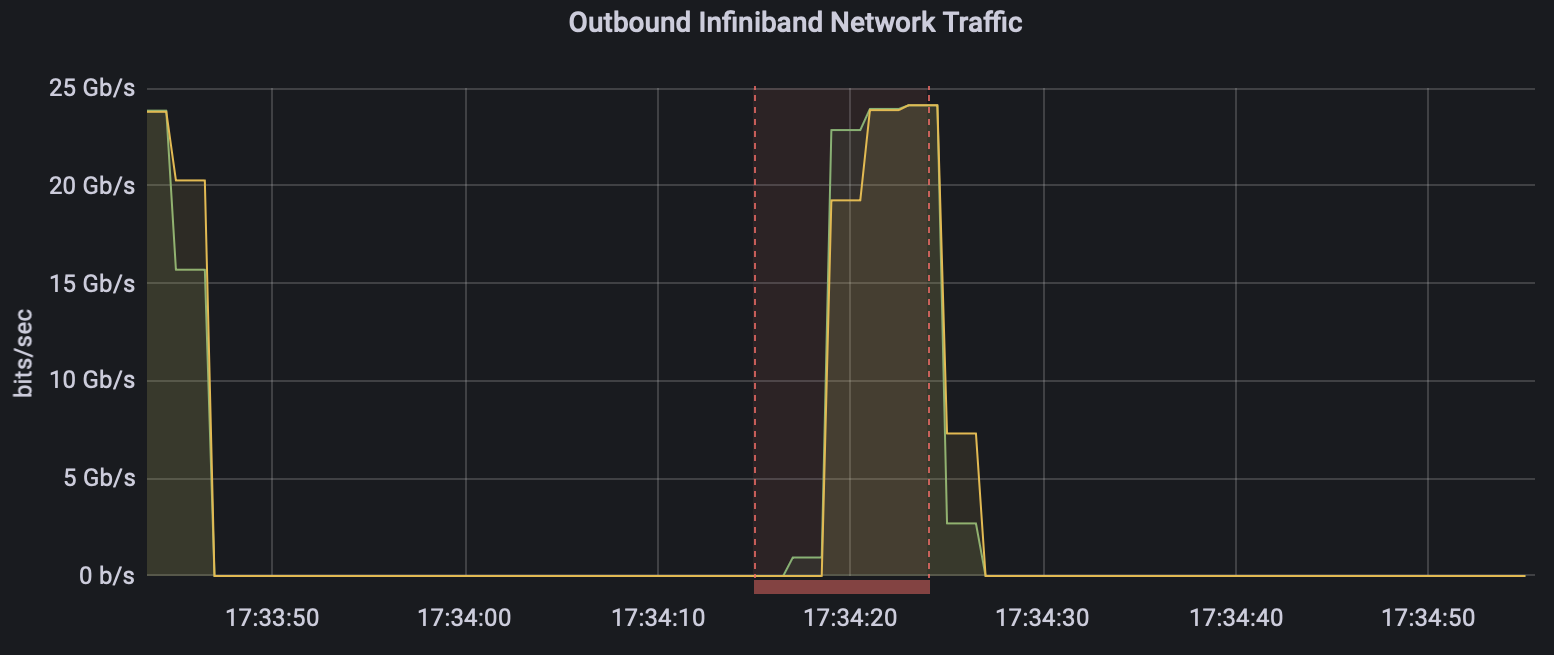
Yep, just as we suspected! Most traffic, if not all, is going over RoCE. This is the same if we set UCX_NET_DEVICES to eth0, eth1, foo, or anything else at all. Very strange behaviour indeed. It appears that the devices specified with UCX are being ignored by OpenMPI. An interesting aside is the fact that the PingPong latencies for these rogue benchmarks are consistently a little longer than the default or when we specify the Mellanox NIC directly. Whatever mechanism OpenMPI is falling back on is unoptimal.
A deeper dive into Open MPI
To understand why setting UCX_NET_DEVICES gives us unexpected and seemingly incorrect performance, a deeper dive into OpenMPI’s architecture might help us. OpenMPI is built from a Modular Component Architecture (MCA), a series of modules, components, and frameworks pieced together at run-time to create an MPI implementation. Each of these components is responsible for a specific aspect of MPI functionality. We're interested in the components that supply support for RDMA, and their priorities within the MCA.
As of OpenMPI 4.x (the version we are running is 4.1.5) four separate components supporting IB, RoCE, and/or iWARP are potentially available:
- openib BTL
- ucx PML
- hcoll coll
- ofi MTL
It's very important to know the option flags our instance of OpenMPI was compiled with. We can find this out with
ompi_info | grep Configure
Configure command line: '--prefix=/opt/ohpc/pub/mpi/openmpi4-gnu12/4.1.5'
'--disable-static' '--enable-builtin-atomics'
'--with-sge' '--enable-mpi-cxx'
'--with-hwloc=/opt/ohpc/pub/libs/hwloc'
'--with-libfabric=/opt/ohpc/pub/mpi/libfabric/1.18.0'
'--with-ucx=/opt/ohpc/pub/mpi/ucx-ohpc/1.14.0'
'--without-verbs' '--with-tm=/opt/pbs/'
An effort is being made to streamline the components and as of v4.0.0 the UCX PML is the preferred mechanism for running over RoCE-based networks. Consequently the --without-verbs flag in our build (from OpenHPC) disables the openib BTL. OpenMPI 5.x removes the openib BTL entirely. This will clean up some of the uncertainty in how OpenMPI is compiled and the accompanying component priorities for RoCE.
Fixed Configuration
Configuring OpenMPI with
--with-platform=contrib/platform/mellanox/optimized
forces using UCX also with TCP transports when specified. Alternatively we can add the following options to the mpirun command:
-mca pml_ucx_tls any -mca pml_ucx_devices any
This now allows us to correctly set the network device used with UCX_NET_DEVICES as before, with no issues. Finally we can set the net device and get exactly what we expect.
eth0
| PingPong Latency (µs) | PingPong Bandwidth (Mb/sec) |
|---|---|
| 36.12 | 6533.84 |
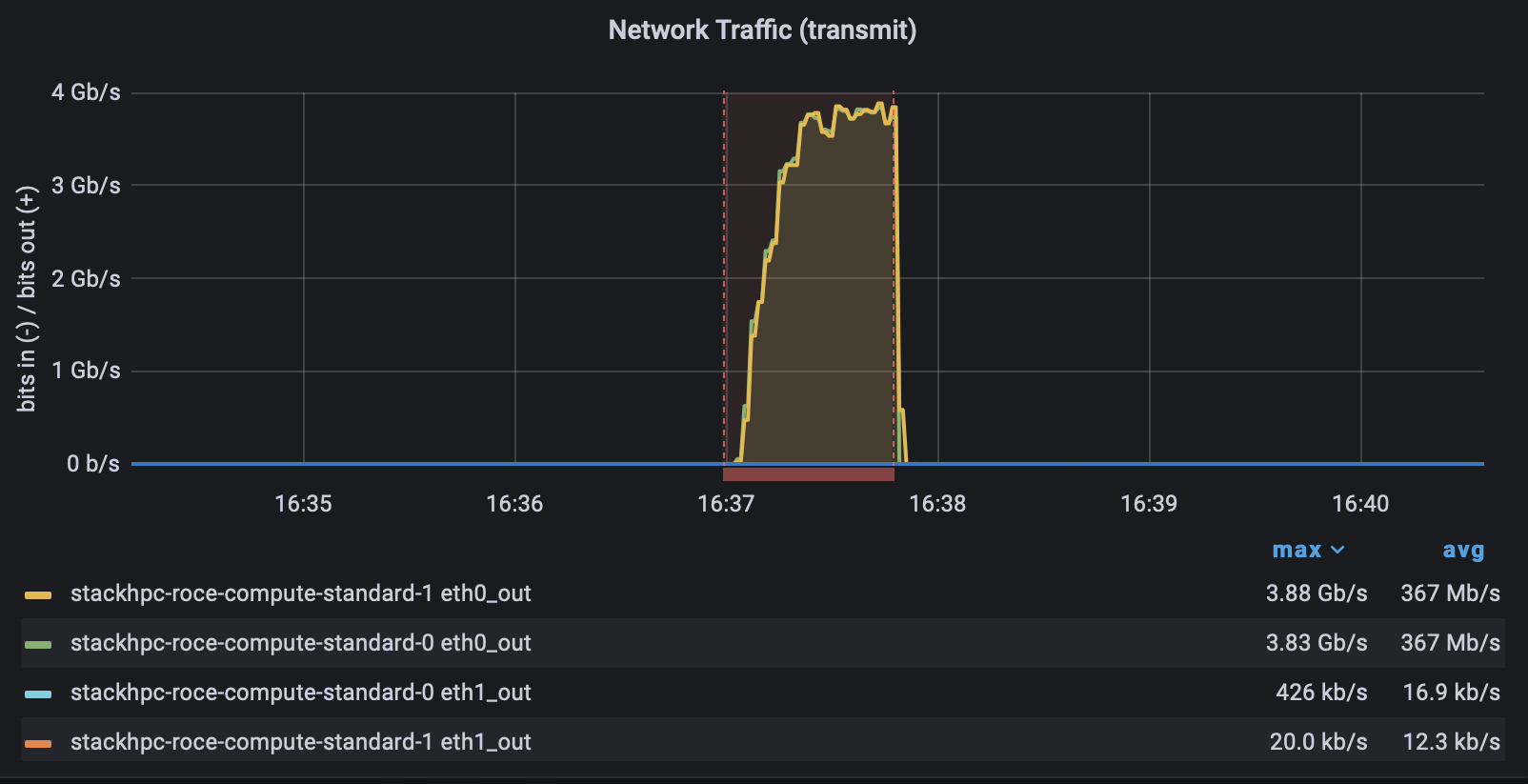
eth1
| PingPong Latency (µs) | PingPong Bandwidth (Mb/sec) |
|---|---|
| 9.44 | 28973.04 |
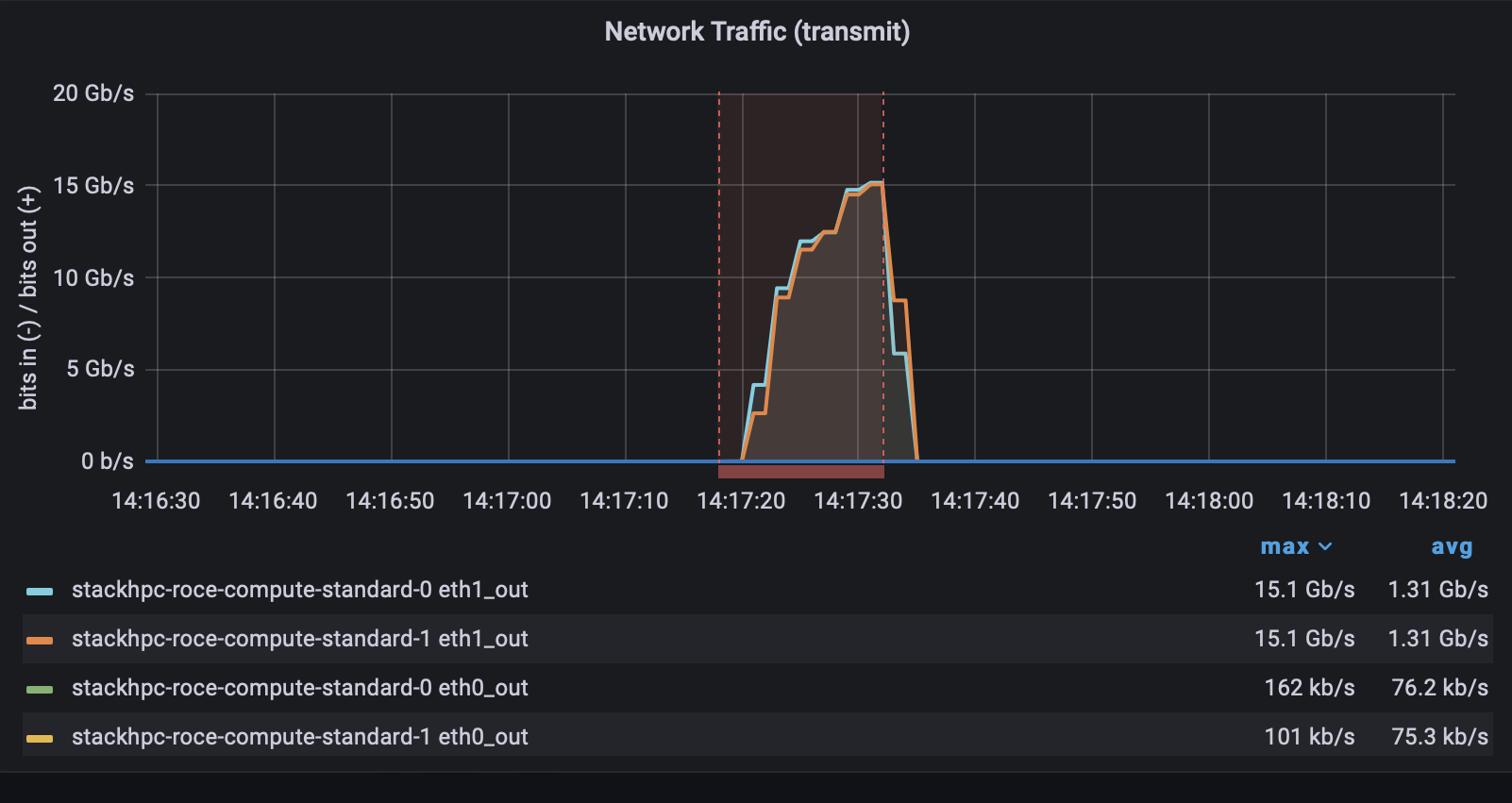
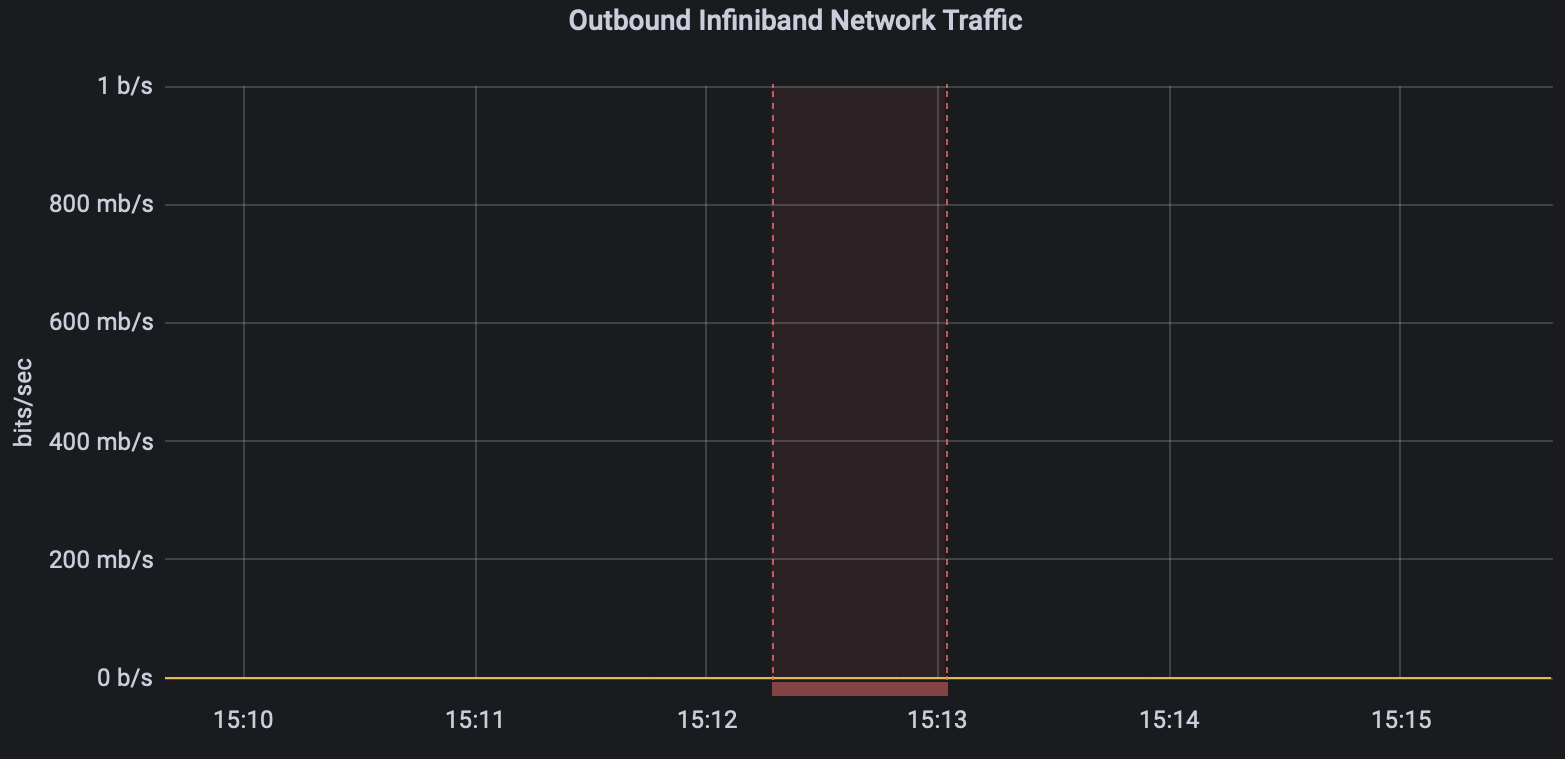
And just to make sure we can see on the Grafana dashboard that no traffic is going via RDMA.
Conclusions
Once a network is RoCE-capable, both the in-kernel and Mellanox drivers make RoCE available to the system with no further configuration in modern Linux distributions. However the MPI stack is still hugely complicated and despite efforts such as priotitising the UCX component to make it simpler for users, ensuring it is running as desired is not straightforward. Experimentation is necessary, having monitoring is crucial, and users need documented "known-good" configurations to base their own workloads on.
Many thanks to the UCX and OpenMPI developers for their help in investigating and understanding the behaviour described here!