For optimal reading, please switch to desktop mode.
The meteoric rise of large language models (LLMs) and generative AI over the past 18 months has taken the technology world by storm. Everyone (and their grandpa) is desperate to get their hands on the latest GPUs or to experiment with the newest proprietary LLM offerings from companies such as OpenAI. However, despite the hype, there have been numerous warnings regarding the downsides of these powerful new tools; such as the potential for privacy violations or just getting their 'facts' in a muddle [1] (admittedly, some stories do make for entertaining reading).
Thankfully, the emerging trend of open-sourcing large language models, such as Llama 2, is helping to democratise access and offers a potential remedy to some of these issues. In particular, open models provide the opportunity for companies and large institutions to run private LLM services on in-house infrastructure; helping to allay privacy concerns as well as providing a controlled environment in which to educate users on both the positive aspects and the potential pitfalls of this emerging technology.
In this post we discuss how to get started with deploying LLMs on private cloud infrastructure thanks to StackHPC's new Helm chart and associated Azimuth application template which simplifies the deployment process significantly and allows anyone to run their own in-house LLM service with ease, or to research the potential of this exploding technology.
The Simplicity offered by Azimuth
Kubernetes is widely regarded as the gold standard for running complex and resilient production workloads and services. However, as explained aptly by Llama 2 in the screenshot below, setting up a Kubernetes cluster on which to run services such as LLMs can be a complicated task.
Fortunately, Azimuth can help! As explained in one of our previous articles, Azimuth is a self-service portal which simplifies the management of cloud resources for scientific computing and AI use cases. Part of Azimuth's offering is a curated catalogue of pre-packaged application templates, many of which are designed to be run on a Kubernetes cluster. As such, Azimuth also provides an intuitive user-interface for provisioning those underlying clusters by entering a few simple configuration options into the provided template.
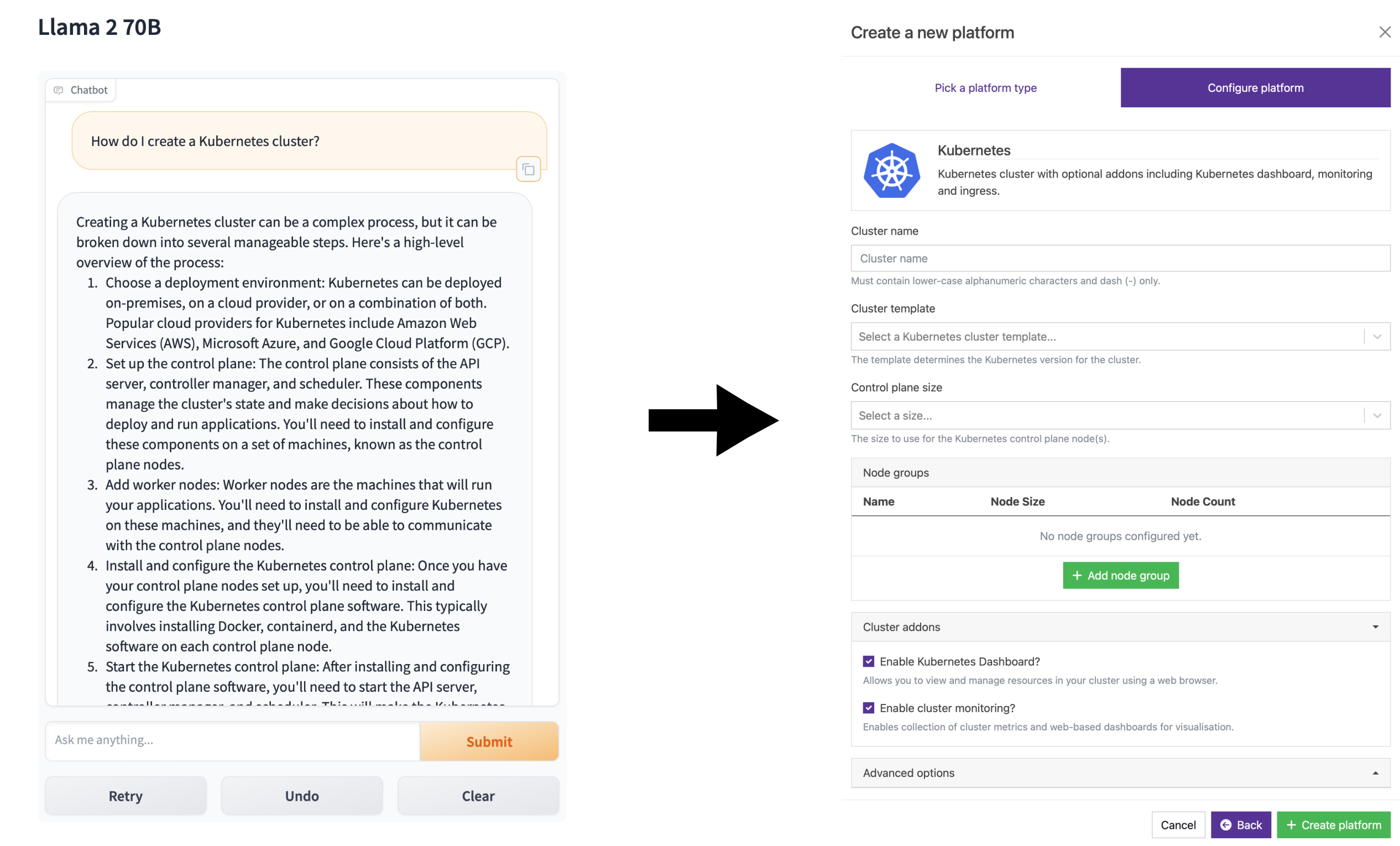
Furthermore, thanks to the power of ClusterAPI and StackHPC's open-source CAPI Helm Charts, Azimuth-provisioned Kubernetes clusters provide auto-healing, auto-scaling, a standard monitoring stack and automatic bootstrapping of GPU dependencies (courtesy of the Nvidia GPU operator). All of which combine to make for a painless experience when deploying and managing Kubernetes clusters.
Having provisioned a GPU-equipped cluster with just a few clicks, all that's left to do is to configure and deploy the Large Language Model. In an upcoming Azimuth release, this will be as simple as selecting the LLM application from the catalogue and entering the desired configuration options.
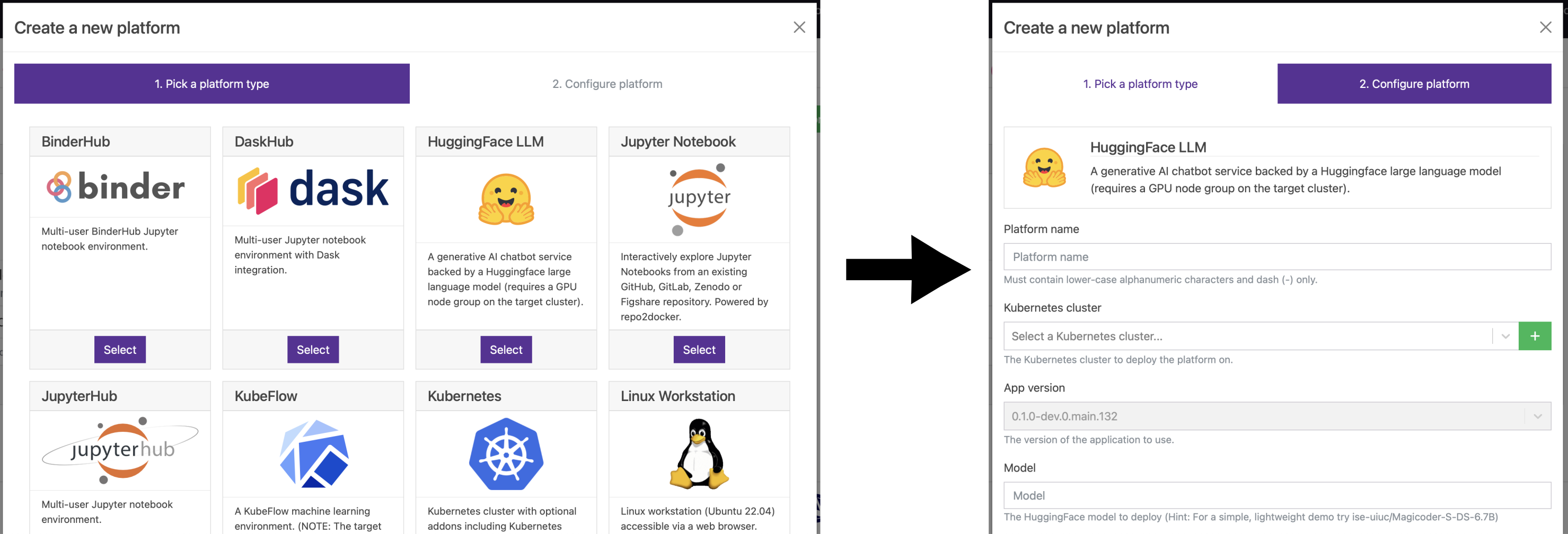
Depending on the size of the chosen language model, the initial deployment of the app can take some time, since the model weights must be downloaded from HuggingFace and stored locally on the cluster before they can be loaded into GPU memory. The progress of this download can be monitored by viewing the logs for the LLM API pod, either via the provided Kubernetes Dashboard or by downloading the provided kubeconfig file for the cluster.
Using your shiny new language model
Once the model weights are downloaded, the application is ready to use! The simplest way to interact with the deployed model is through the provided chat interface which can be accessed from the link in the 'Services' section of the application card.
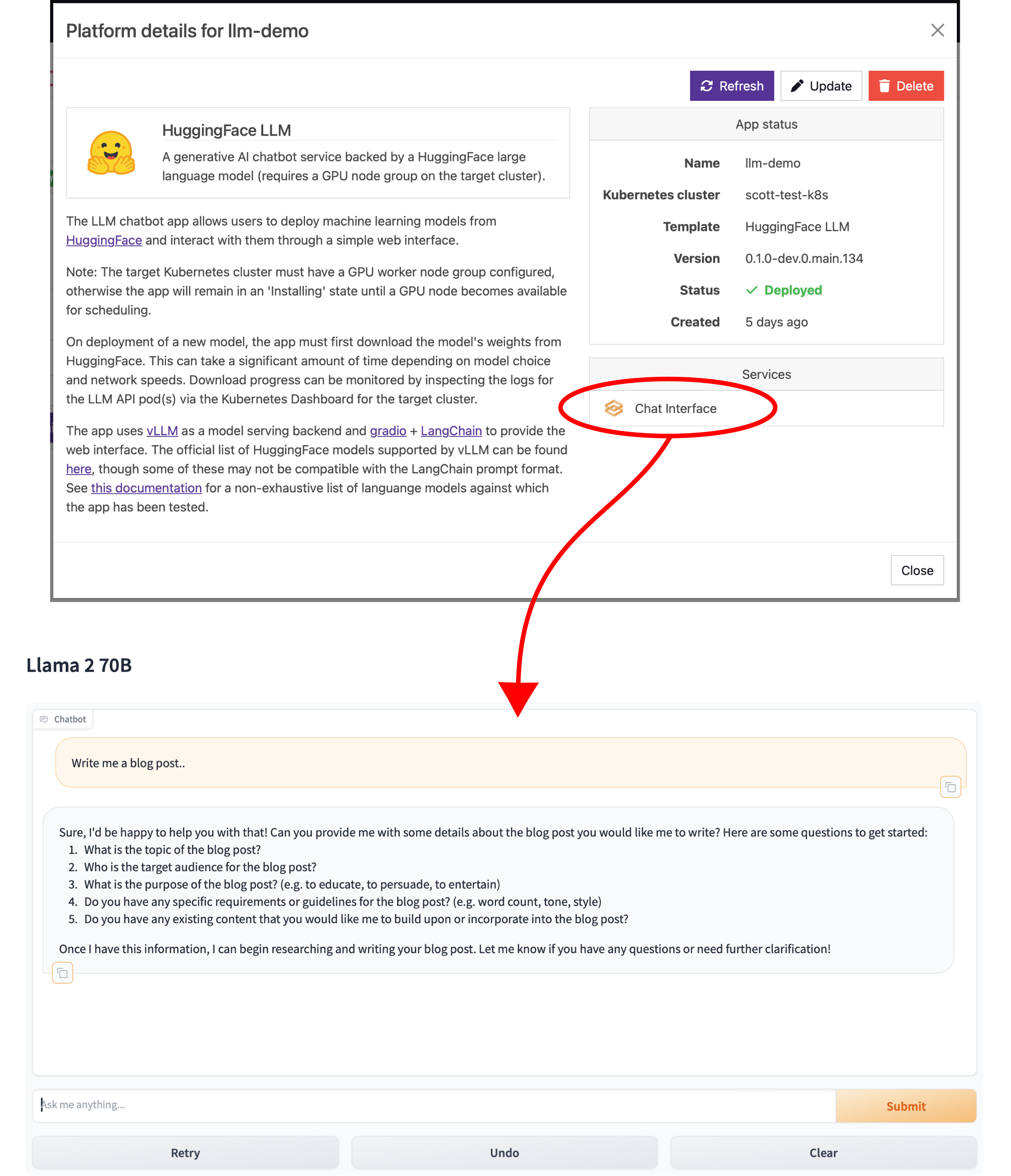
Just like any other Azimuth application, the chat interface automatically benefits from the standard authentication and access management features provided by the Azimuth Identity Provider. The provider is built on top of Keycloak and allows Azimuth administrators to set up fine-grained access controls to specify which users or groups can access each Azimuth-deployed application. Federation with external identity providers (or manual account creation in Keycloak) is also possible to configure, allowing admins to grant users access to the application's chat interface without granting them any view of, or access to, the underlying cloud infrastructure (i.e. the Kubernetes cluster).
Interacting with deployed LLMs programmatically
Owing to the fact that the LLM application is fundamentally just a Helm chart installed on a Kubernetes cluster, with frontend and backend components accessed via Kubernetes Services, other applications running on the same Kubernetes cluster can easily interact with the deployed language model. For example, we can use Azimuth to deploy a JupyterHub instance onto the same cluster and make direct requests to the language model backend via its in-cluster address:
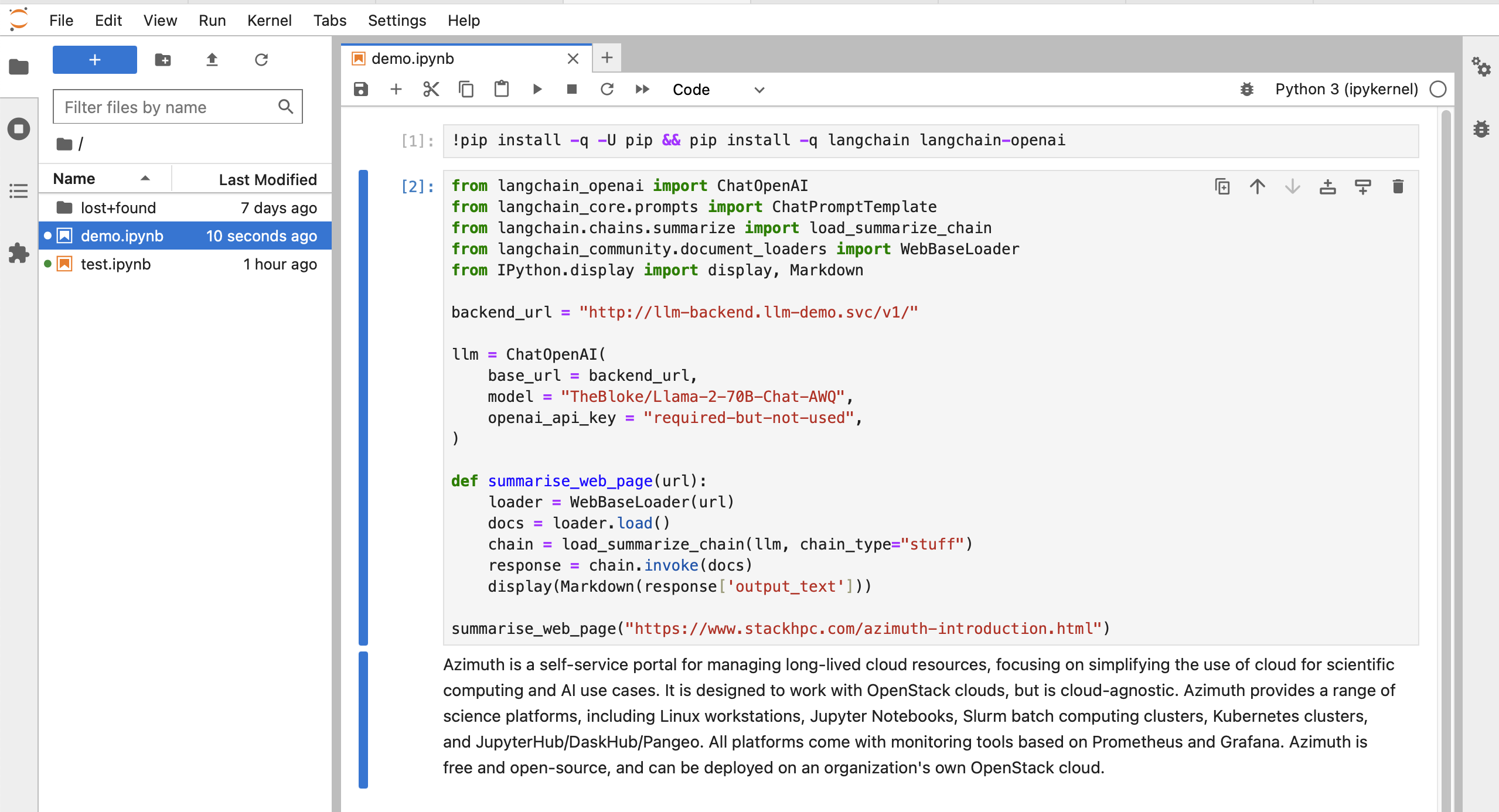
This access pattern opens up a wide variety of interesting possibilities, such as using Retrieval-Augmented Generation (RAG) to create in-house chatbots, coding assistants or automation pipelines with direct access to internal documents or wiki pages - without the associated privacy concerns of sending private or proprietary information to an external source (e.g. OpenAI).
Deployment outside of Azimuth
If you have an existing Kubernetes cluster, or would prefer to deploy a cluster without using Azimuth, then the LLM Helm chart can also be installed manually. The instructions for doing so, along with various other technical details regarding the application's architecture plus a non-exhaustive list of tested language models, can be found in the Helm chart repository.
Conclusion
Whether we like it or not, when it comes to large language models and generative AI, the metaphorical horse has well and truly bolted from the stable. It therefore seems prudent to develop tools which enable operators to maintain maximum control over how users interact with, and share information with, these new and potentially powerful technologies. Deploying private services on in-house infrastructure is, in our view, the best way to achieve this.
In this blog post, we have discussed the challenges of deploying large language models and introduced our new Helm chart and Azimuth application template which simplify the deployment of LLM services on private infrastructure. We also demonstrated the convenient chat interface which is deployed alongside the LLM, as well as an example of interacting with the deployed model programmatically, opening up possibilities for creating in-house chatbots, coding assistants, or automation pipelines without privacy concerns.
Acknowledgements
StackHPC greatly appreciate the generous support of Cambridge University in providing compute resources to enable the development of our open-source Azimuth platform and the support of the Humboldt University of Berlin in the development of the LLM application in particular.
Get in touch
If you would like to get in touch we would love to hear from you. Reach out to us via Bluesky, LinkedIn or directly via our contact page.
Footnotes
| [1] | If we're being pedantic, 'facts' have no meaning here since LLMs don't have a concept of true or false; they simply generate plausible sounding continuations (based on their training data) of the input text that is fed to them - but that's a rant for another day... This is one of the important limitations that users can hopefully learn by deploying and experimenting with their own LLMs thanks to Azimuth! |
| [*] | Disclaimer: The title for this blog post and some sections of the concluding paragraph were written by a large language model... |