For optimal reading, please switch to desktop mode.

Change is inevitable. Servers get repurposed. We don't always get quite the hardware that we asked for, with occasional early mortality, misconfiguration or simple inconsistency between servers supplied by a vendor. As such, it is important to consider that a system which is intended to have identical components may in fact have hidden differences. It is possible to gather hardware introspection data with both Kayobe (via Bifrost) and user-space Ironic. At StackHPC, we use this data extensively during infrastructure commissioning, as documented previously in this blog. However, using this data to identify server discrepancies has always been challenging, and reviewing this data can be a particularly daunting task.
ADVise - Anomaly Detection Visualiser
We have developed ADVise (Anomaly Detection VISualisEr). This tool will analyse hardware introspection data and provide graphs and summaries to help you identify unexpected hardware and performance anomalies. ADVise follows a two-pronged approach. It will extract and visualise differences between the reported hardware attributes, and will analyse and graph any benchmarked performance metrics.
Hardware Attributes
Here we have an anonymised case study on a selection of 143 compute nodes that are intended to be identical systems. Through the use of ADVise, we instead found five nodes which stray from the collective. The manufacturer has provided an unexpected gift, one node has a newer motherboard version to the rest. Three of the nodes were previously used as controllers, and after being recommissioned as compute nodes, they still require a BIOS update. We also found two nodes which were not reporting any logical cores, one of which specifically had multithreading disabled. While only some of these anomalies are critical enough to require further action, they are all worth being aware of.
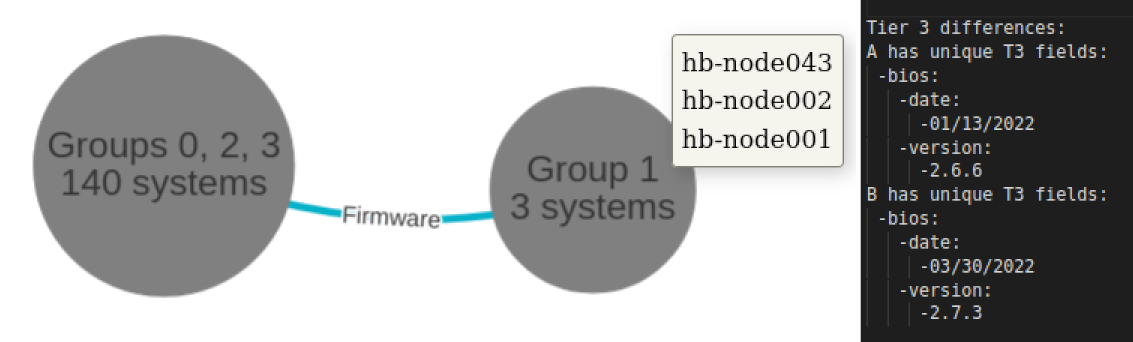
Systems grouping, with a difference in firmware. Difference visualisation (left) and data on the differing values (right).
Benchmarking for Anomalies in Performance
ADVise also analyses the benchmarking data to identify any potentially abnormal behaviour. Groups may have a high variance in performance, which could indicate some issues as identical hardware should be expected to perform roughly at the same level. The tool also highlights where individual nodes may be over/underperforming compared to the rest of the group. This could warrant further investigation into potential causes of this behaviour, particularly if a node is found to be consistently underperforming. The plot below is an example of how anomalous data may appear. In this case, a few nodes were marked as underperforming outliers on a memory benchmark. We can then review the rest of the memory benchmark data on this group. The remaining benchmarks did not have any outliers, suggesting that there are not any faults with the memory of the systems.
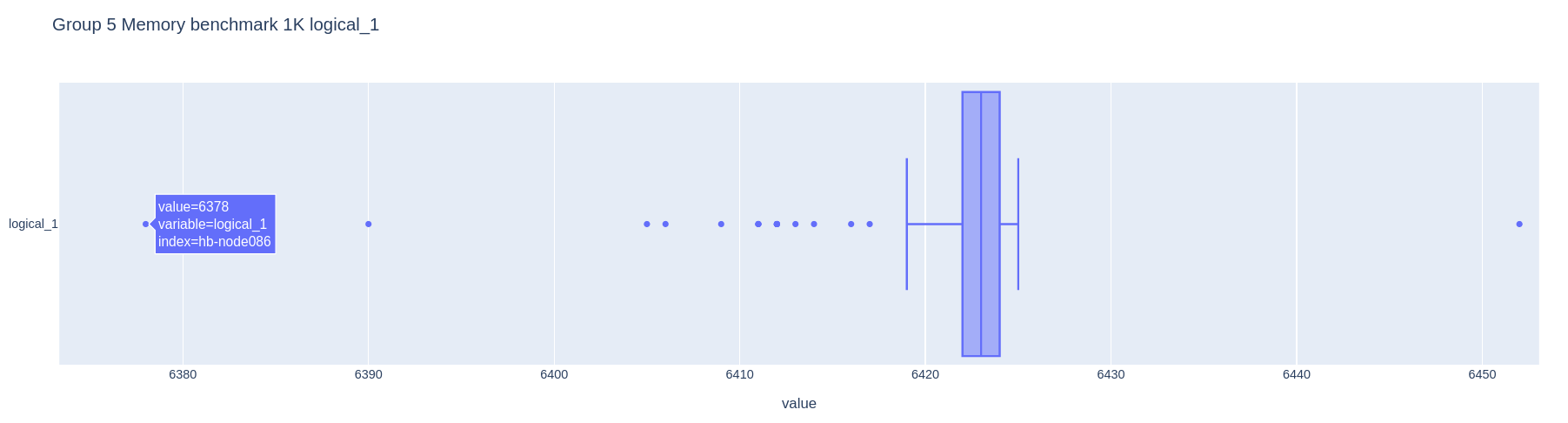
Box plot of a memory benchmark across the compute nodes. In these plots, the box itself covers the 25th to 75th percentiles. The whiskers extend to the furthest datapoint within 1.5 times the interquartile range. Outliers beyond this are plotted as individual points. Two nodes are seen to be particularly significant outliers.

List of other memory benchmarks on the same group. These are marked as 'CONSISTENT', indicating that there are no outlier nodes.
While this was only one isolated instance, multiple plots showing the same node as an outlier would indicate statistical significance. If a node is consistently underperforming across all metrics, this could suggest that an external factor is hampering performance. For example we’ve previously encountered offline power supplies, which caused some servers to slow. While these performance metrics cannot always identify causes, they do allow for us to be aware that the issues even exist, and help to narrow down which nodes need our attention.
When working with large-scale systems, things will never be in the exact state that we would like. With the help of ADVise, we can discover where expectations differ from reality and manage hardware differences before they cause problems.
Credit
ADVise revives the package cardiff from https://github.com/redhat-cip/hardware/, with thanks and appreciation to its original author.
ADVise integrates the package mungetout from https://github.com/stackhpc/mungetout.
Get in touch
If you would like to get in touch we would love to hear from you. Reach out to us via Bluesky or directly via our contact page.