For optimal reading, please switch to desktop mode.
Five years ago, StackHPC conducted and published an initial study on Kubernetes, HPC and MPI. Last year, we presented research at KubeCon 2022 Detroit on Kubernetes, RDMA and OpenStack. In this post, StackHPC summer intern William Tripp presents his investigation into Kubernetes and Slurm.
The Slurm Workload Manager is a widely used job scheduler in HPC clusters yet, to the best of our knowledge, the path towards a production-ready, containerised version of Slurm running on Kubernetes has remained relatively unexplored. We suspect that this is partly due to apparent design mismatches arising from Slurm's roots in a world of stable, long-lived "nodes", versus the Kubernetes world of modular, replaceable containers. However, our experience with the (non-Kubernetes-based) StackHPC Slurm Appliance HPC environment has shown there are a number of potential benefits to combining these two technologies. Firstly, at its heart creating and operating a Slurm cluster requires the build, deployment and configuration of many pieces of software across multiple physical or virtual servers, and management of the connectivity between them. These are exactly the problems the Kubernetes ecosystem tackles, and it provides powerful tools for all of these areas. Secondly, Kubernetes' autoscaling capabilities provide some interesting possibilities for implementing Slurm in hybrid private/public cloud environments, relying on Kubernetes to provide a common API. Finally, a Kubernetes-based Slurm would simplify integration with the StackHPC Azimuth self-service platform portal which makes it trivial to deploy Kubernetes applications packaged with Helm.
In this blog post, we provide a detailed account of our ongoing R&D work to explore the viability, benefits and drawbacks of deploying containerised Slurm on Kubernetes. The source code for the project can be found here and includes a pre-packaged Helm chart for convenient deployment.
Implementation
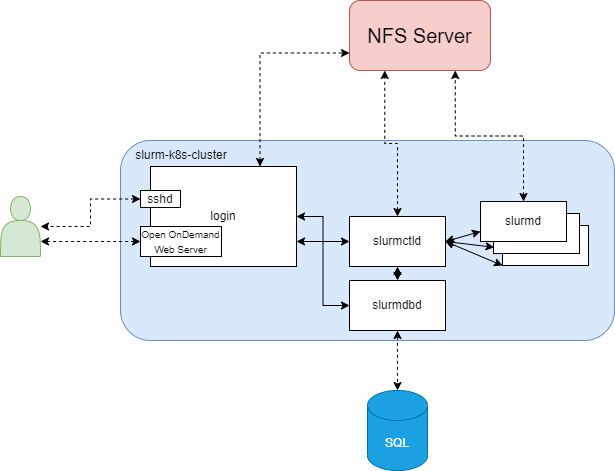
A traditional Slurm deployment contains a number of task-specific daemons. The obvious approach to running Slurm on Kubernetes is therefore to provide a separate pod for each daemon. This leads to the following pods:
- slurmctld - A single pod running the control daemon responsible for managing the job queue, monitoring worker nodes and allocating resources.
- slurmd - Multiple pods running the daemon for worker nodes.
- slurmdbd - A single pod providing the interface to the database used for persisting accounting records.
In addition to these core containerised services, we include the following components to mimic other important aspects of a traditional Slurm cluster:
- login - A pod which provides users access to Slurm commands and a shared work directory. It also provides an Open OnDemand web portal, as well as SSH access to the cluster, both of which can be accessed externally via a LoadBalancer service.
- mysql - A database pod for storing accounting records, backed by a Kubernetes PVC. Alternatively, an externally managed database can be specified in the Helm chart instead of this pod.
As Slurm requires a shared filesystem, we also developed a Helm chart for installing RookNFS. This can be installed to provide a Read-Write-Many (RWX)-capable storage class for testing and development, although the RookNFS operator has been deprecated and is no longer maintained.
Starting from a fork of an existing Slurm container cluster for docker compose, we migrated it to Kubernetes, developed a Helm chart and began the process of productionising various aspects of the cluster. For the sake of simplicity, the Slurm cluster is currently a single user system, as users must be created and configured inside of the login container, but extending this to allow multiple users is a logical next step.
Containerisation Considerations
In this implementation, each of the nodes in a Slurm cluster is mapped to a Kubernetes pod as described above, and each pod runs a single container. But most "real" Slurm nodes will run multiple services - for example a login node requires Munge for authentication of Slurm communications, an SSH daemon, and an Apache web server to serve the Open OnDemand portal, while a worker node requires at least Munge and the slurmd daemon. This is currently implemented using a container entrypoint script to run the necessary binaries directly. While this is simple, it does impose some limitations on logging and service management.
Another quirk of containerising Slurm is the need to run the slurmd containers as privileged. A common use case of Slurm clusters is to run containerised HPC workloads using a container system such as Apptainer or Singularity. These systems work by mounting bind paths from the host file system (which in this case is also a container!) into the workload container. This requires that the slurmd container has a privileged security context - granting a non-privileged container capabilities is not sufficent. This is not considered a major issue as it is no worse than for a non-containerised Slurm cluster, and Slurm provides its own isolation of workload processes. However the Slurm cluster should be deployed on its own dedicated Kubernetes cluster to prevent potential security issues. Ideally, some further investigation would be carried out to discover what is required to allow non-privileged containers to be used here.
Slurm Worker Node / Pod Configuration
A key design consideration for the migration to Kubernetes was how to ensure that the slurmd Kubernetes pods appeared as "Slurm worker nodes" with the correct behaviours. This had various aspects to it.
Firstly, the StatefulSet API was chosen to manage the pods; while Slurm worker nodes don't necessarily require state, StatefulSets provide stable, predictable pod names which can be used as Slurm node names, and are nicely abbreviated to a "hostlist expression" such as slurmd-[0-10] in the Slurm CLI tools. The slurmd daemons themselves are started as a Dynamic Node using the -Z option. Such nodes are automatically added to the list of Slurm nodes and do not need to be defined in the slurm.conf configuration file, making integration with the Helm cluster definition much simplier. Crucially, by default such nodes register with the same CPU and memory configuration as the system they are running on, meaning Slurm will correctly schedule jobs requesting multiple "CPUs" (in Slurm's terminology, basically a core) or specific amounts of memory.
Secondly, as host networking is used for the slurmd pods (discussed below), the hostnames in a pod are in fact the Kubernetes node name. The -N nodename option is therefore used to set the Slurm nodename from the pod name instead of the hostname, with the pod name injected as an environment variable via the downward API.
Thirdly, DNS resolution of the slurmd pod names is provided by defining a headless service. Name resolution from the slurmd pods to the other containers is provided by setting a pod DNS policy of ClusterFirstWithHostNet.
Lastly, we ensure only a single slurmd pod is run per Kubernetes node by defining the slurmd port on 6818 as requiring a hostPort.
Workflow and deployment speed
In order to facilitate efficient development of the project, a Github Actions CI pipeline was created to build a container image containing the components needed for the deployment of a Slurm cluster. It was configured to run when changes to the image are pushed to the source repository, using Docker Buildx caching to ensure fast build times. The fast build process and Kubernetes' ease of deployment to all machines meant that we saw a significant increase in productivity when developing this project compared to other Slurm projects at StackHPC. All previously built images were also stored on GitHub Container Registry tagged with the commit under which they were built, allowing for effective version control the image used in the Helm chart without the need for rebuilds.
Configurability
For a Slurm cluster that would be used in production, it is important for cluster administrators to be able to reconfigure the cluster and cycle secrets without needing to rebuild containers and ideally without having to restart running pods. The natural solution is to mount configuration files and secrets into the containers as Kubernetes ConfigMaps and Secrets respectively but this has some limitations in this context. Firstly, several individual configuration files and secrets for the Slurm cluster must be mounted into existing, populated directories, as opposed to volume mounts. While Kubernetes can do this by specifying a subPath, changes to ConfigMaps mounted this way are not propagated without restarting pods. Secondly, several configuration and secret files require specific permissions and user ownerships, which Kubernetes' container security contexts are not flexible enough to grant at a pod manifest level. This means that copies of these files must be made from their mounts upon pod startup, again meaning that changes are not propagated without a pod restart. Finally, even for volume mounts with no specific permissions or ownership requirements, there can be a delay before changes are propagated to the cluster, meaning that cluster admins may attempt to reconfigure Slurm and see no effect.
Attempts were made to mitigate these issues by managing secrets via Helm wherever possible. Secrets such as the database password, Munge key and login node host ssh keys, which aren't intended to be remembered by humans or frequently changed, are auto-generated by Helm pre-install hooks. Unless a serious security breach occurs, secrets such as these should require no manual configuration or reconfiguration.
Preventing Job Loss
The pod restarts described above are potentially dangerous for a Slurm cluster, as running Slurm jobs are unlikely to recover from their Slurm worker nodes being taken down mid-execution. The solution implemented here was to include Kubernetes jobs as Helm hooks which enforce safe upgrades:
- A pre-upgrade hook sets all worker nodes to DRAIN state, meaning that running jobs will continue but no further jobs can be scheduled onto them.
- The same hook checks for any running or completing jobs in the Slurm queue, and fails if they are found, preventing the upgrade. The previous DRAIN step prevents any race condition in this check.
- A post-upgrade hook undrains all worker nodes, allowing them to accept queued jobs again.
This allows for upgrades to safely be made to the Kubernetes cluster without needing to manually drain the Slurm cluster for maintenance, or the need to consider the state of Slurm within the containers from a Kubernetes administration point of view.
Autoscaling
A key benefit of Kubernetes that would be desirable to exploit with Slurm is its autoscaling capabilities. Automatic provisioning of machines in response to Slurm jobs is a clear application of combining the two. Autoscaling needed to be implemented at both the Slurm and Kubernetes levels.
- Slurm can can run executables or scripts to "power up" worker nodes if required to service queued jobs and "power down" idle nodes. By providing the Slurm controller pod with a service token for the Kubernetes cluster and a template of the slurmd pods, it was possible to have Slurm make calls to the kube-apiserver to create or destroy slurmd pods as needed. One non-obvious detail here is that the -b flag must be passed to the slurmd deamon on startup; the Slurm node's uptime is checked on registration and without this registation does not complete due to the container's uptime being the Kubernetes node's uptime.
- At the Kubernetes cluster level, the StackHPC Azimuth portal provides self-service ClusterAPI-provisioned Kubernetes workload clusters. These support creation of new Kubernetes worker nodes if resource constraints prevent pods from being scheduled on the existing Kubernetes cluster.
As we force Kubernetes to schedule one slurmd pod per Kubernetes node (via the definition of a hostPort as discussed above), a request for a new slurmd pod automatically means a new Kubernetes worker node is required.
While the Slurm side of autoscaling is conceptually simple, making this robust in an unreliable cloud environment can be quite tricky. Here operating on Kubernetes is an advantage, as container creation will retry, automatically recovering from transient errors. This means that even if container creation "times out" from the Slurm point of view, resulting in the Slurm node being marked as DOWN, if it later succeeds the Slurm node will automatically go back to IDLE state, without any explicit error handling being required. However it is likely there are still some rough edges in our implementation, and hence currently autoscaling support is still a work in progress.
MPI, Performance and Host Networking
Parallel applications using a Message Passing Interface (MPI) are a key workload for many Slurm clusters, so it was important
this worked for a containerised Slurm. Our implementation demonstrates support for OpenMPI, for
jobs launched using either OpenMPI's own mpirun launcher or Slurm's srun command (via PMIX).
Our containerised Slurm initially ran MPI jobs to completion but the jobs' output logs contained the following errors:
slurmd-0:rank0: PSM3 can't open nic unit: 0 (err=23)
slurmd-0:rank0.mpitests-IMB-MPI1: Failed to get eth0 (unit 0) cpu set
--------------------------------------------------------------------------
Open MPI failed an OFI Libfabric library call (fi_endpoint). This is highly
unusual; your job may behave unpredictably (and/or abort) after this.
Local host: slurmd-0
Location: mtl_ofi_component.c:513
Error: Invalid argument (22)
--------------------------------------------------------------------------
slurmd-1:rank1: PSM3 can't open nic unit: 0 (err=23)
slurmd-1:rank1.mpitests-IMB-MPI1: Failed to get eth0 (unit 0) cpu set
We were unable to determine the exact source of these errors, but configuring the slurmd pods to use host networking rather than the Kubernetes default CNI seemed to prevent these issues. We suspect that the errors were likely related to the way in which MPI's NAT translations interact with our Kubernetes pods. This had the added side effect of providing consistent performance improvements to MPI workloads. A benchmark was taken for MPI performance on our Slurm cluster using Intel's PingPong MPI Benchmark to determine how much was retained by the containerised implementation. These results come with the caveat that the cloud used to obtain these benchmarks has been experiencing networking issues and will likely not be fully representative of the peak performance of the cluster. A benchmark of the performance of the same cloud was also taken independently of Slurm using our kube-perftest tool Also included - although not a "fair" comparision - is our non-containerised Slurm Appliance using VM nodes on an RDMA over converged Ethernet (RoCE) network. This is around the performance that would ideally be obtained with the containerised implementation, and further testing under similar conditions is required to see how much performance is truly lost with this the containerised implementation.
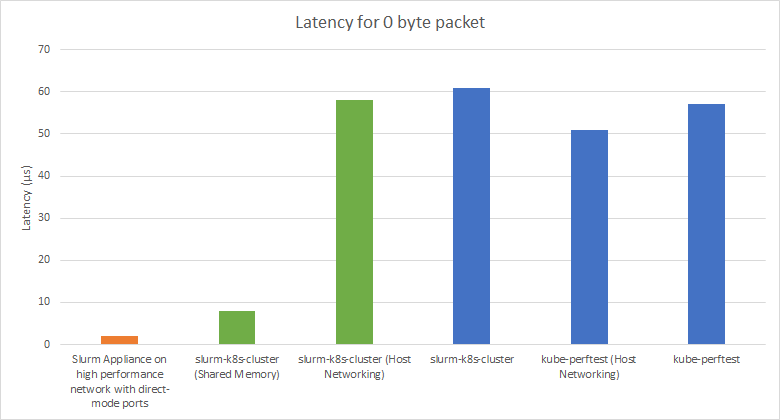
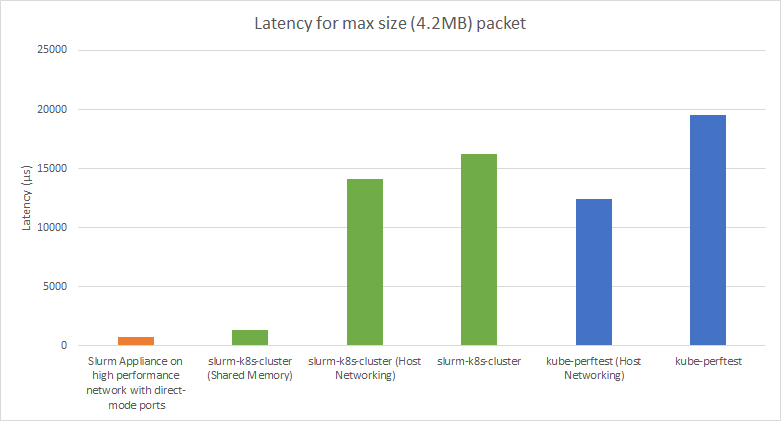
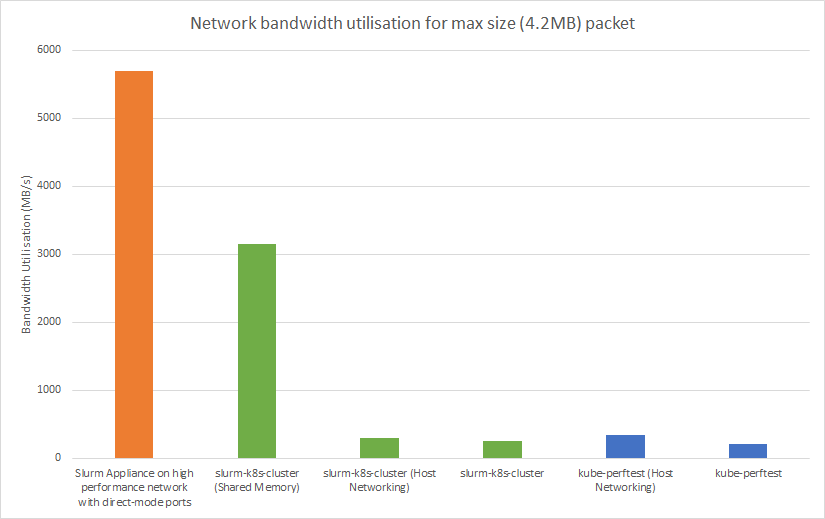
As you can see, while performance is significantly below what would be expected from a traditional high performance Slurm cluster, it is consistent with baseline performance of the network it was deployed on, with differences being small to the point of likely being attributable to noise. It can also be seen that host networking consistently makes a noticeable and consistent impact on performance due to reduced overhead from not having to perform NAT translations.
Containerised Interactive Apps
Further exploration was made of containerising cluster services by experimenting with running containerised interactive apps on top of our containerised
Slurm cluster. The Open OnDemand web portal allows you to provide "apps", which launch as jobs on worker nodes of your cluster. It currently
provides a demo app for running Jupyter notebooks on worker nodes, but it requires Jupyter to be installed on them. A fork of
this app was developed to launch a containerised version of Jupyter via Apptainer, in order to avoid bloating our Slurm image and to see how viable it was. This worked by having the Jupyter container bind to a localhost port and then forwarding traffic to it from an internally exposed port on the Slurm worker nodes through an OnDemand reverse proxy on the login node.
The main deviation from a standard Jupyter deployment was the need to propagate the DNS name of the node into the container so that the Jupyter server could register on a URL that met Open OnDemand's requirements for the reverse proxy. Due to the way in which DNS names are configured on the Kubernetes cluster, the app is currently more tightly-coupled to our Slurm cluster implementation than we would like, but it can in principle be repurposed for other clusters by modifying the templates/before.sh.erb and form.yml files in the source code.
What's Next?
The next logical steps for the project are extending it to a multi-user system, as this is likely to be a hard requirement for many HPC clusters. A back-to-back investigation of any performance lost due to containerisation is also required, which is likely to involve developing support for RDMA networking within the Kubernetes cluster hosting the Slurm deployment.
Conclusion
Overall, the project has shown that a working, containerised Slurm cluster running on Kubernetes is indeed possible and is able to utilise features of the Kubernetes ecosystem effectively. In particular, the development and operation experience is signficantly enhanced by container image builds using Dockerfiles, configuration via ConfigMaps and Secrets and operations via Helm and the k9s terminal UI. We believe that the project may have strong use cases in development environments and for scalable HPC Slurm clusters.

StackHPC congratulates William on a successful summer internship, with many useful findings from his research project. Good luck with your studies and hopefully we'll see you again soon William!
Get in touch
If you would like to get in touch we would love to hear from you. Reach out to us via Bluesky, LinkedIn or directly via our contact page.