For optimal reading, please switch to desktop mode.
This is the second [first one here] of a trilogy of blogs on the use of modern Ethernet stacks (sometimes referred to as the generic term High Performance Ethernet) as a viable alternative to other interconnects such as Infiniband in HPC and AI. The reasons and motivations for this are many:
- Modern Ethernet stacks support RDMA and as such come close to the base latencies (critical to the performance of a bona fide HPC network) of alternative technologies, viz. order 1µs
- Convergence of NIC hardware used in both Ethernet and Infiniband mean that the delay in higher line rate Ethernet technologies is not as great as previous generations
- Ethernet as an IEEE standard means that suppliers of innovative storage and new AI acceleration technologies choose Ethernet by default.
- In virtualised contexts, the properties of Ethernet in supporting VLAN extensions significantly enhances security and multi-tenancy without the performance penalties, albeit to some extent IB pkeys can also be used.
- If Ethernet can address these aspects, then the complexity of medium-sized systems can be reduced, saving cost, time and risk as only one data transport is required along with the control networks which are always Ethernet. I say medium-sized systems as there is still a question relating to congestion management at large-scale (see previous blog) together with the scalability of global reduction operations without hardware offload.
For StackHPC, the standard nature of Ethernet, however, has potential for some interesting side-effects, unless care is taken on ensuring optimisation of the configuration. The focus of this blog, explores these aspects and draws upon many years of experience of the team in SDN and HPC. We also assess these aspects in a novel manner in particular by extensive use of hardware monitoring of the application and the network stack. We also note here that we are only considering the case of bare metal. In the case of virtualised compute, we point you to the following article on advances in performance and functionality using SR-IOV.
Previously we had compared and contrasted the performance of 25GbE and 100Gbps EDR for a range of benchmarks up to 8 nodes. Our experience with “medium” scale HPC operations with customers over the past 5 years suggests that a typical operational profile of applications running would indicate that 8 nodes represents a good median and in fact one that remains pretty constant as new node types (potentially doubling the number of cores) are purchased or new nodes with acceleration are introduced.
Of course as a median, there may well exist power-users who say they need (or probably more correctly want) the capability of the whole machine for a single application - such as a time-critical scientific deadline - and while such black swan events do occur, they are, ipso facto, not common. Hence the focus here on medium-sized (or high-end systems) the largest tranche of the HPC market.
Thus in this article we extend the results firstly up to and including a single Top-of-Rack switch for both Ethernet and IB and then to explore the performance across multiple racks. Typically, but subject to data centre constraints this ranges from 56 to 128 nodes (two-to-three racks worth), or around the 1-2MUSD price tag (disclaimer here), probably representing 80% of the HPC/AI market.
In doing this however, we of course need to be cognisant of the following caveats, given the test equipment to hand. So, here we go.
- The system under test (SUT) comprises multiple racks of 56 nodes of Cascade Lake with each node comprising a dual NIC configured as one 50GbE and one 100Gbps HDR. These are Mellanox ConnectX-6. Each interface is connected to a Mellanox Cumulus SN3700 and a Mellanox HDR-200 IB Switch respectively.
- Each Top-of-rack switch is then connected in a Leaf-Spine topology with the following over-subscription ratio. For Ethernet this is 14:1 and for IB this is 2.3:1.
- Priority Flow Control was configured on the network, with MTU set at 9000.
As an aside, there is an excellent overview on these networking aspects at Down Under Geophysical’s blog (I’ve tagged blog #3 here). The reader is also pointed at the RoCE vs IB comparison here.
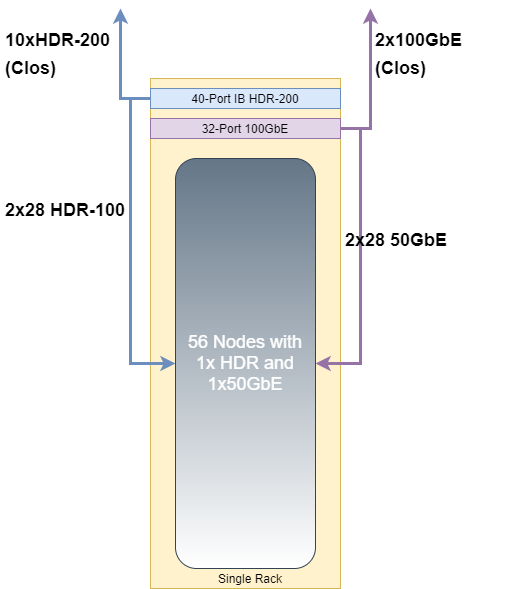
The system is built from the ground-up using OpenStack and the OpenStack Ironic bare-metal service and has applied to the base infrastructure, an OpenHPC v2 Slurm Ansible playbook to create the necessary platform. Performance of the individual nodes is captured by a sophisticated life-cycle management process ensuring that components are only entered into service once they have transitioned through a set of health and performance checks. More on that to come in subsequent blogs.
The resulting system provides a cloud-native HPC environment that provides a great deal of software defined flexibility for the customer. For this analysis it provided a convenient programmatic interface for manipulation of switch configurations and easy deployment of Prometheus-Redfish service stack for monitoring of the nodes and Ethernet switches within the system. This provided an invaluable service in debugging the environment.
Given these hardware characteristics and depending (that dreadful verb again) on the application we use, we would expect the inter-switch performance will be governed by the bi-sectional ratios of b) above together with the additional inter-switch links (ISLs) ratio .
As yet we have not been able to find an application/data-set combination in which there is a significant difference between IB and RoCE as we scale up nodes. So here, we again focus on using Linpack as the base test as we know that network performance and in particular bi-sectional bandwidth is a strong influence on scalability, and we should be able to expose this with the application. N.B. The system as a whole reached #98 in the most recent (November 2020) top500 list - more details are available here but save to say this result was with IB.
However, let's first start with base latencies and bandwidth for a MPI pingpong.
| Network | PingPong Latency (microseconds) | PingPong Bandwidth (MB/sec) |
|---|---|---|
| IB 100Gbps | 1.09 | 12069.36 |
| ROCE 50Gbps | 1.49 | 5738.79 |
[sources: IB, RoCE]. We note here that the switch latency between IB and RoCE is also included in this measure. This would be higher in the case of the latter and again is a factor to consider at scale.
Secondly, we now compare the performance within a single rack. The final headline numbers are shown in the Table below, but how we got there is an interesting journey.
Single Rack 56 nodes
| Network | GFLOPS (Linpack) |
|---|---|
| IB 100Gbps | 1.34976e+05 |
| ROCE 50Gbps | 1.33943e+05 |
NB. that the RoCE number at 50Gbps is within 99% of the IB number.
The first step in the analysis was to make sure we could more easily toggle between the types of interconnect. Previously with tests we had used openmpi3 and the pmi layer within Slurm. For this SUT we decided to use the UCX transport. This provides a much easier way to select the interconnect, however we did find out an interesting side-effect when using a system with this transport, as without a specific setting to configure the mlx5_[0,1] interface, the run-time assumes the system to be a dual-rail configuration with a perverse unintended consequence.
Evidence of the behaviour was determined by observing node metrics and in particular system CPU combined with metrics from the Ethernet switch. The attached screenshot shows this behaviour and was a compelling diagnostic tool as multiple engineers were involved in the configuration and set-up.
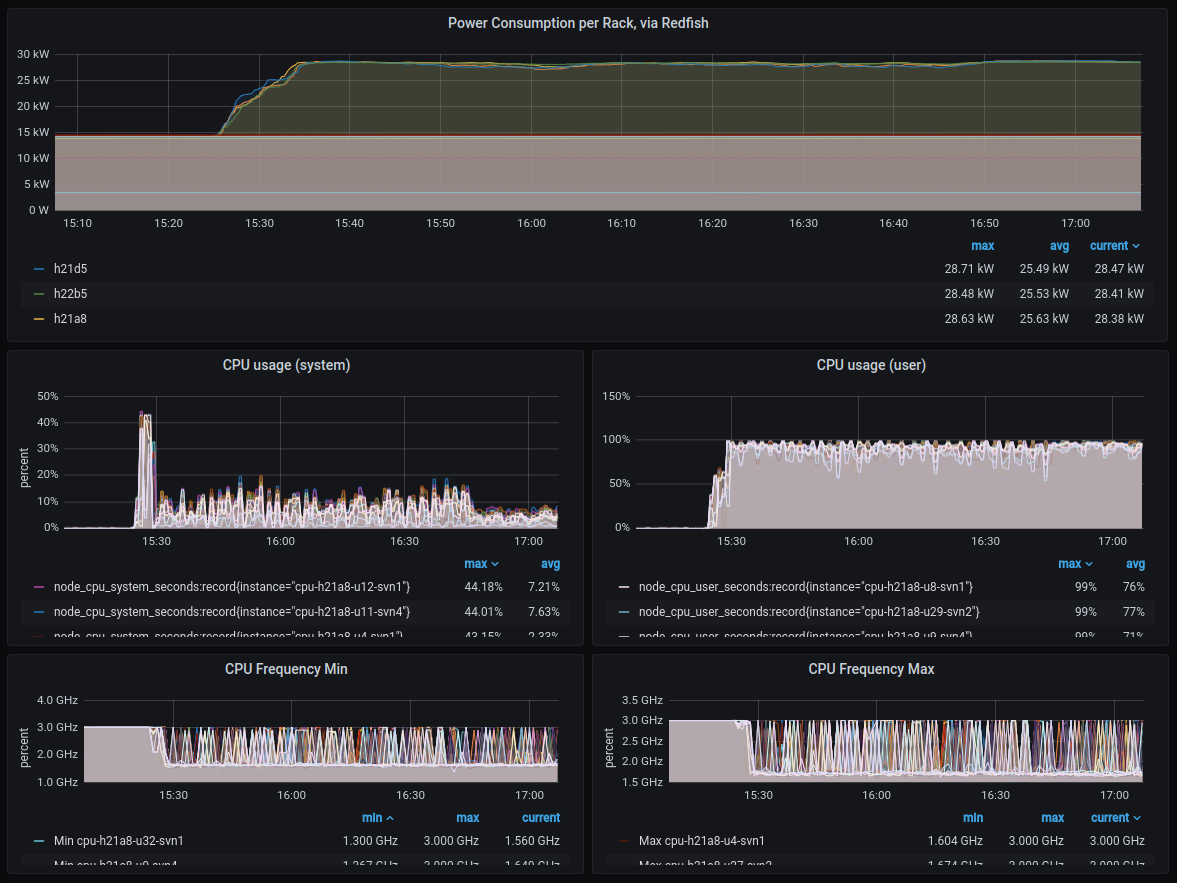
Here we observe a system CPU pattern, not observed in previous experiments where system CPU is flat and near zero and user CPU flat at 100%. On a different dashboard we were also monitoring Ethernet traffic through the switch as well as packets through the different mlx devices. This quickly resolved the issue of unintended dual-rail behaviour.
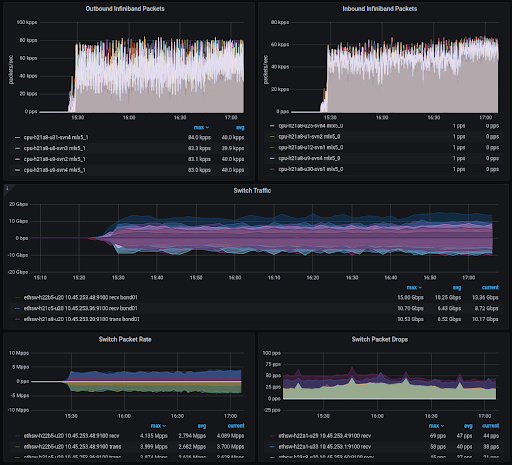
Once we had resolved the single rack performance we moved on to multiple rack measurements, where armed with the appropriate dashboards we can begin to monitor the effects due to bi-sectional bandwidth.
The results are shown in the graph below. Between 1 and 2 Racks the performance is within 99% of the IB performance irrespective even taking into account the reduced bisectional bandwidth.
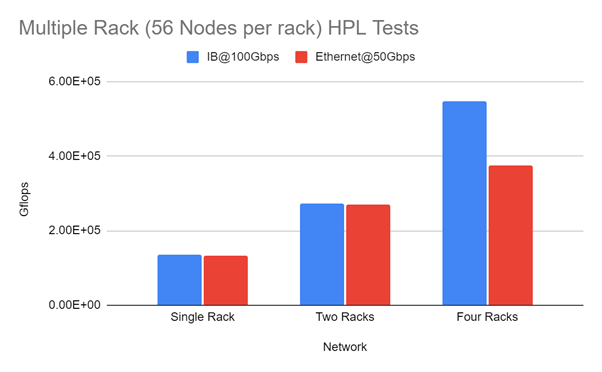
We are building up a body of evidence in terms of RoCE vs IB performance and will be adding further information as more application performance is gained. These data are being documented at the following github and will be detailed in subsequent blogs. Further work will also look at I/O performance.
Of course, many stalwarts of HPC interconnects will remain in the IB camp (and for good reason) but we still see many organisations moving from IB to Ethernet in the middle of the HPC pyramid. We also expect the number of options in the market to increase in the next two years.
Acknowledgements
We would like to take this opportunity to thank members of the University of Cambridge, University Information Services for help and support in this article.
Get in touch
If you would like to get in touch we would love to hear from you. Reach out to us via Bluesky or directly via our contact page.