For optimal reading, please switch to desktop mode.
This is a story about how changes outside our control forced us to take a big pile of carefully-planned JIRA tickets outside and burn them. More usefully, its also a story about what we've done to prevent that happening again ...
Background: The Slurm Appliance
Back in 2021 we blogged about our Slurm appliance batch scheduler cluster environment. Things have moved on since then and the feature set has expanded but the core remains the same. We use OpenTofu (replacing Terraform used at launch) to create virtualised or baremetal nodes, servers or instances. Then we run Ansible against those instances to configure them with the Slurm daemons, monitoring stack, filesystems, identity and network services etc. etc. to provide an operational HPC environment.
At launch, the appliance used CentOS 8 - this was pre CentOS Stream. Early on in development we added configurations for Hashicorp's Packer to allow us to build machine images containing all the packages the appliance needed. Both the CentOS repositories and the OpenHPC repositories we used for Slurm and MPI packages followed a model where packages could be updated within a minor release, and also only the latest packages were available from mirrors after a new minor release. This created a problem where the packages installed by Ansible would move on between Ansible runs. Building these "fat" machine images containing the required packages fixed this problem, giving us reproducible deployments. New nodes could be added to a cluster or existing nodes re-provisioned without being affected by changes in those upstream repositories. When CentOS Stream launched we followed OpenHPC in moving to RockyLinux, but the same issues and the same approach applied.
Upsets from Upstream
Development continued and the end of 2024 was near when several problems all arose within a few days:
- Testing at a client using Lustre showed that an RDMA verbs header file was missing from their image.
- During debugging the above, we found that using the latest NVIDIA OFED version clashed with the OpenHPC libfabric package required for MPI packages.
- New NVIDIA CUDA packages were released, and our CI builds failed due to an incompatibility with the NVIDIA drivers.
- RockyLinux 9.5 was released, so packages from RockyLinux 9.4 disappeared from mirrors.
- Our automated testing hit an issue with the latest podman package provided by RockyLinux 9.5.
- There was no version of NVIDIA OFED (or DOCA) which worked with RockyLinux 9.5.
The last one was critical, as that meant we couldn't even build images including OFED to begin working on the other problems.
More Passengers for the Release Train
The solution was to leverage the StackHPC Release Train. This provides artifacts for OpenStack installations using a StackHPC-hosted Pulp server called ark. Our use of it here is to get snapshots of upstream package repositories - mirrors of those repositories at particular points in time. The .repo files in the VMs used for the Packer image builds are re-written to point to specific snapshots. This means that now image builds are reproducible too; repeating an image build results in the same packages in the final image. While new snapshots are regularly created in ark, we decide when to use them by changing the snapshots which the build VM .repo files point to. This also means that building new images during feature development will no longer run into - and be forced to address at the same time - issues from package updates, making development cleaner and more predicable.
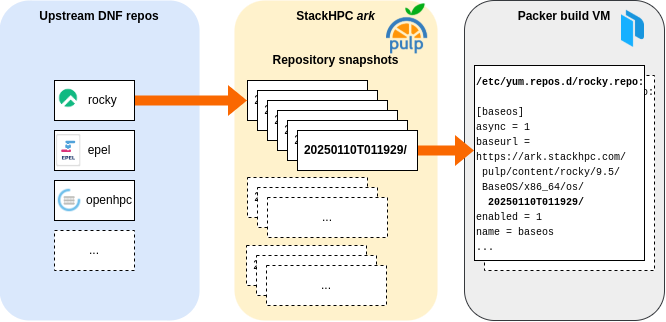
Of course, using ark for builds wasn't quite as simple as re-writing the URLs in the .repo files. For example, some build steps installed the epel-release package, which overwrote our custom EPEL .repo file. And some Ansible tasks running during cluster configuration didn't cope with the fact the ark credentials had been removed from the .repo files at the end of the image build (as these files are user-readable).
These problems were all worked through and finally we could build RockyLinux 9.4 images again, but using packages from ark. Inevitably, almost as soon that was working NVIDIA released OFED and DOCA versions which supported RockyLinux 9.5 and in a sense the original reason for doing this disappeared. However, breaking changes are guaranteed to re-occur with minor version upgrades and we and our clients are now on a sounder footing to cope with them.
At that point we could move on and in a flurry of activity around the Christmas break we also:
- Added support for using NVIDIA DOCA rather than OFED (including rebuilding kernel modules to match installed kernels).
- Added support for using a local Pulp mirror to a) reduce egress charges from ark and b) enable installing packages during cluster deployment, not just during image build.
- Worked around the NVIDIA driver/CUDA package incompatibility.
- Made it easier to add additional site-specific dnf packages and include them in a build.
- Added support for RockyLinux 8.10 via the Release Train.
- Moved support for RockyLinux 9 onto 9.5 with a fix for the podman issue.
- Fixed the issues with Lustre installs and the verbs header file.
Conclusion
All this resulted in probably the largest release for the Slurm appliance to-date. Development continues and a subsequent release has not only added new functionality, but also bumped the ark snapshots - and hence packages - forward. It does contain the groundwork for some interesting new functionality, but that's a story for another time ...